本文最后更新于 4 年前,文中所描述的信息可能已发生改变。
MapReduce编程
- 班级 大数据2201
- 学号 2211650123
- 姓名 宋源博
一、 实验目的
掌握MapReduce处理框架的工作原理和程序开发方法,能够编写MapReduce程序解决单词计数、排序、数据表关联的基本问题。
二、 实验内容
- 掌握Hadoop伪分布式和分布式模式下,基于Yarn的MapReduce任务提交方法与执行原理。
- 掌握基于Mapreduce实现表连接操作的程序
三、 实验方法和步骤
1. 完成分布式集群环境搭建,能够正常使用HDFS和YARN
之前已完成搭建
2.wordcount案例
基础准备
准备文件夹存放和编写测试文件

编写测试文件
编写软件
创建maven工程,MapReduceDemo
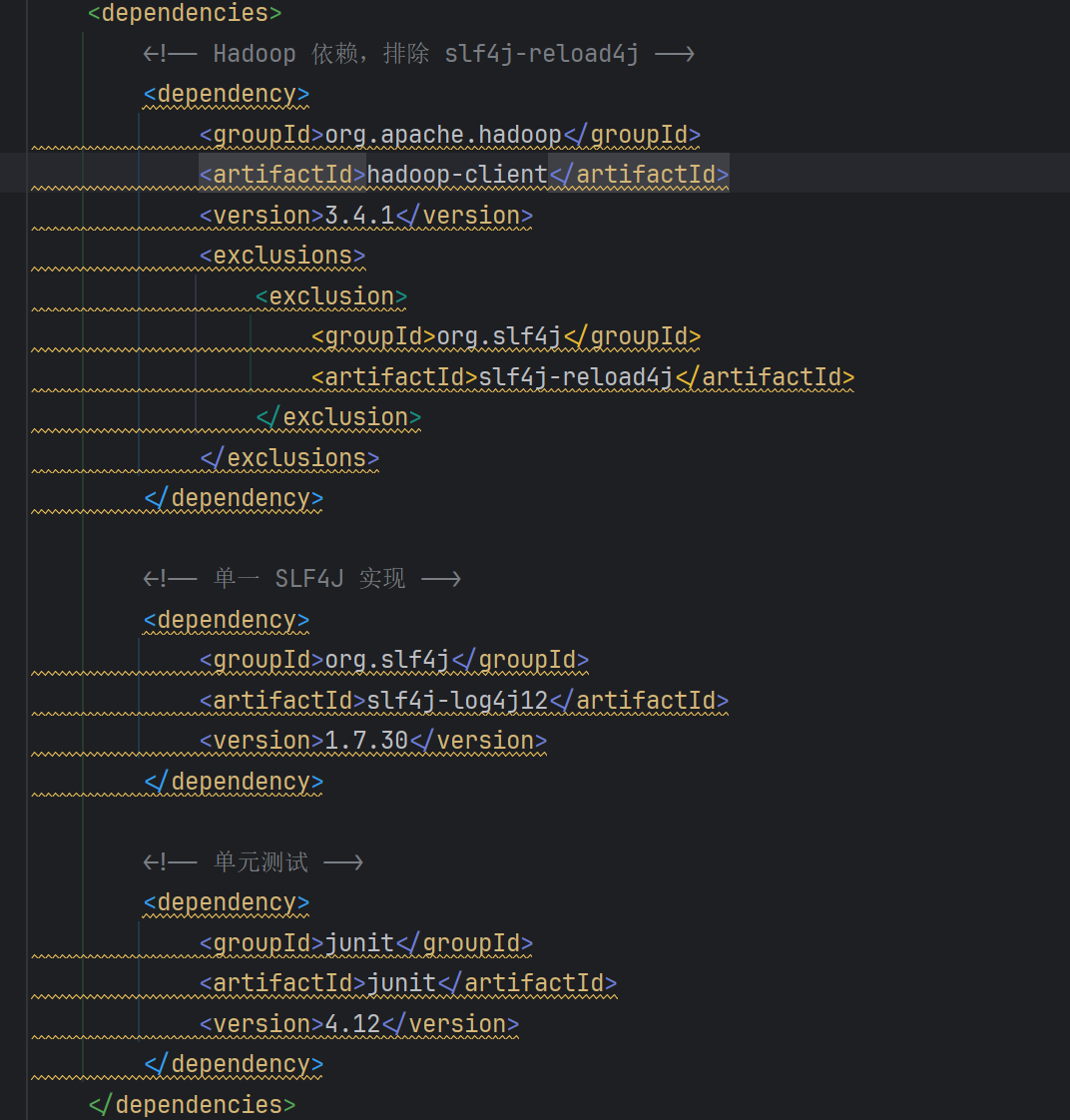
在pom.xml文件中添加如下依赖
由于我使用的是hadoop3.4.1版本,所有我的hadoop自带slf4j,为了实现只实现我的log,所有排除hadoop中的slf4j依赖。
在项目的src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在 文件中填入。
propertieslog4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n创建包名:com.atguigu.mapreduce.wordcount
编写程序
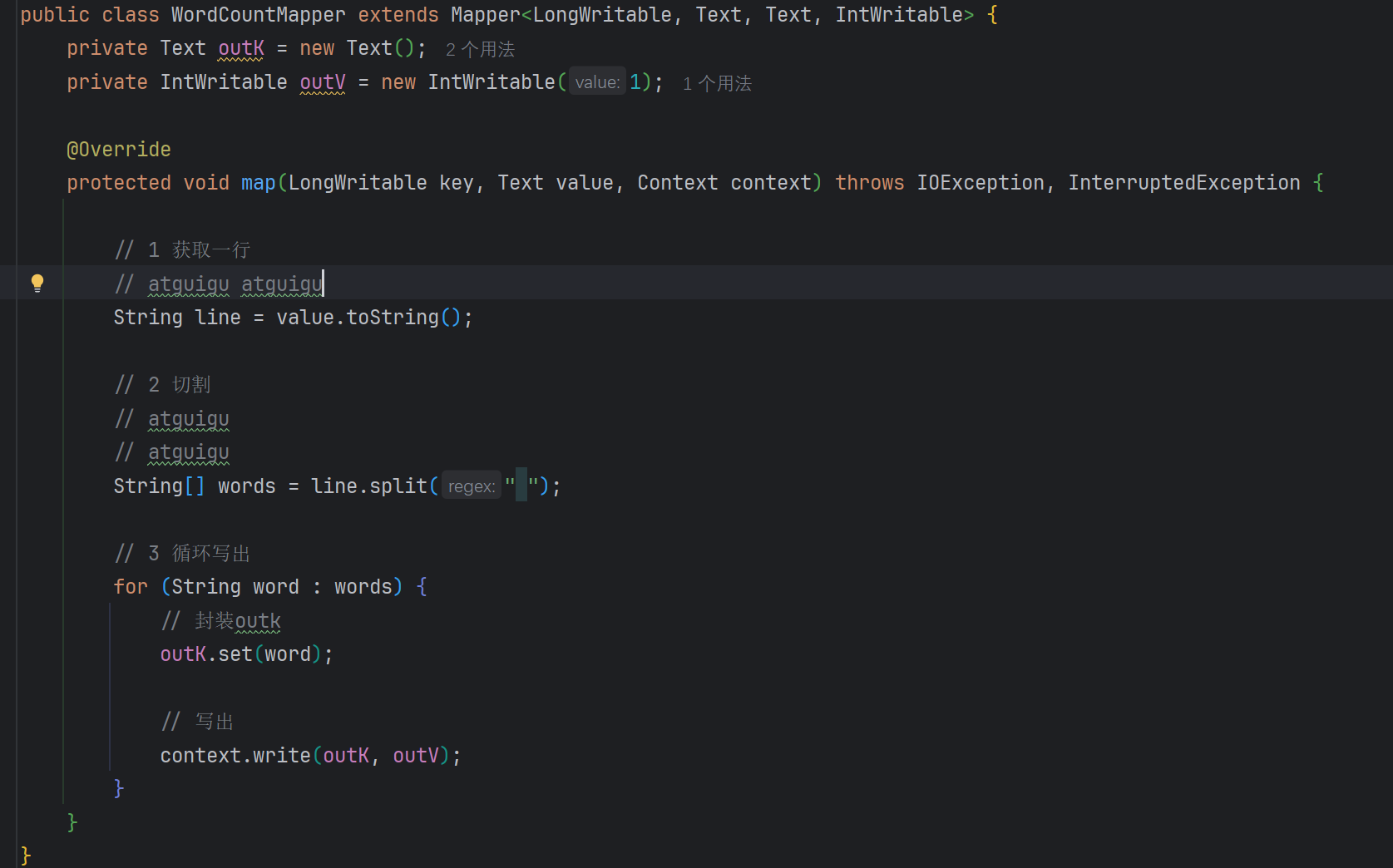
编写Mapper类
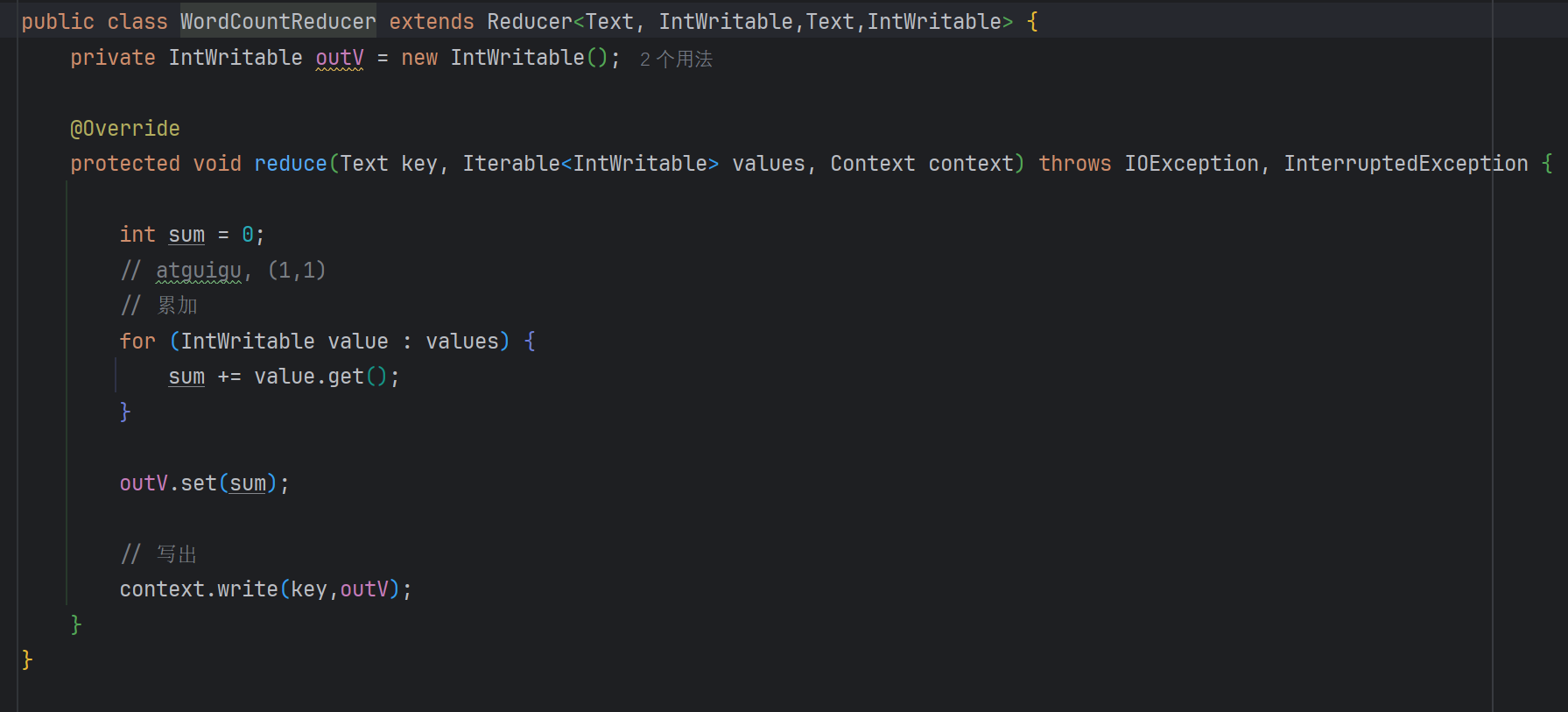
编写Reducer类
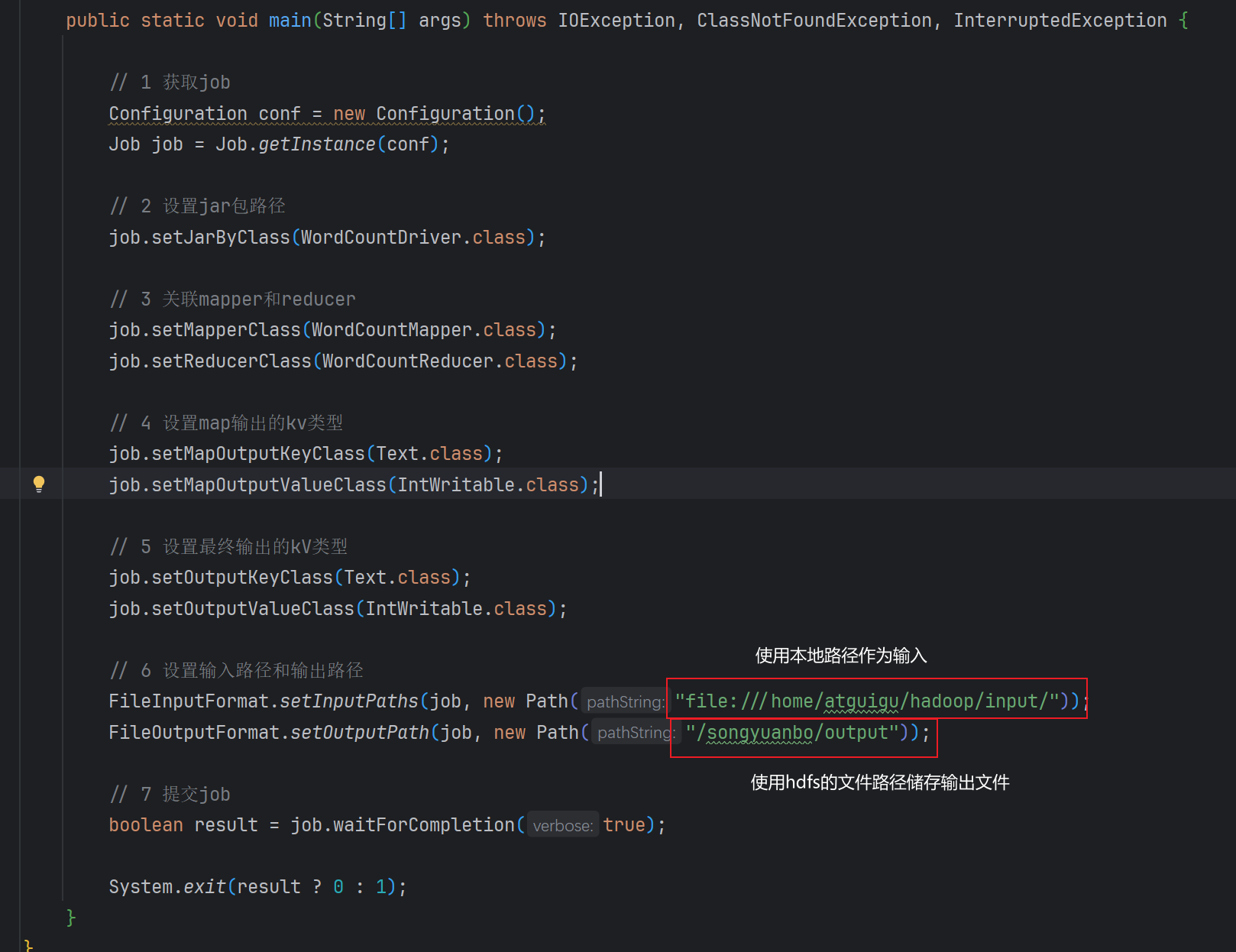
编写Driver驱动类
使用linux本地路径作为输入路径,hdfs的文件路径作为输出路径。
调试软件
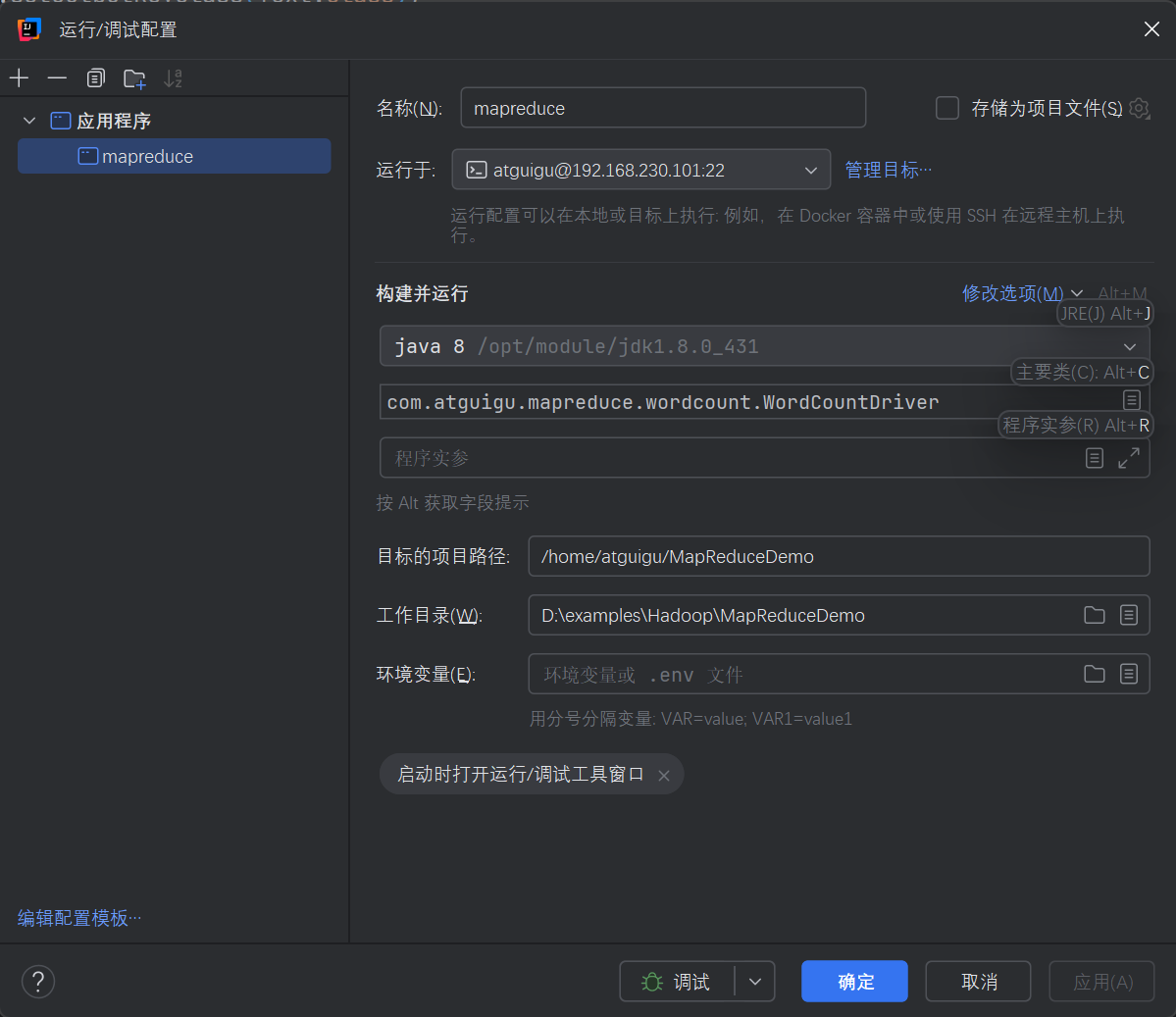
使用idea创建远程调试,本地无需配置环境
新建运行配置,选择对应的java版本和应用的主程序。然后使用ssh将程序运行于linux主机上。
运行测试:
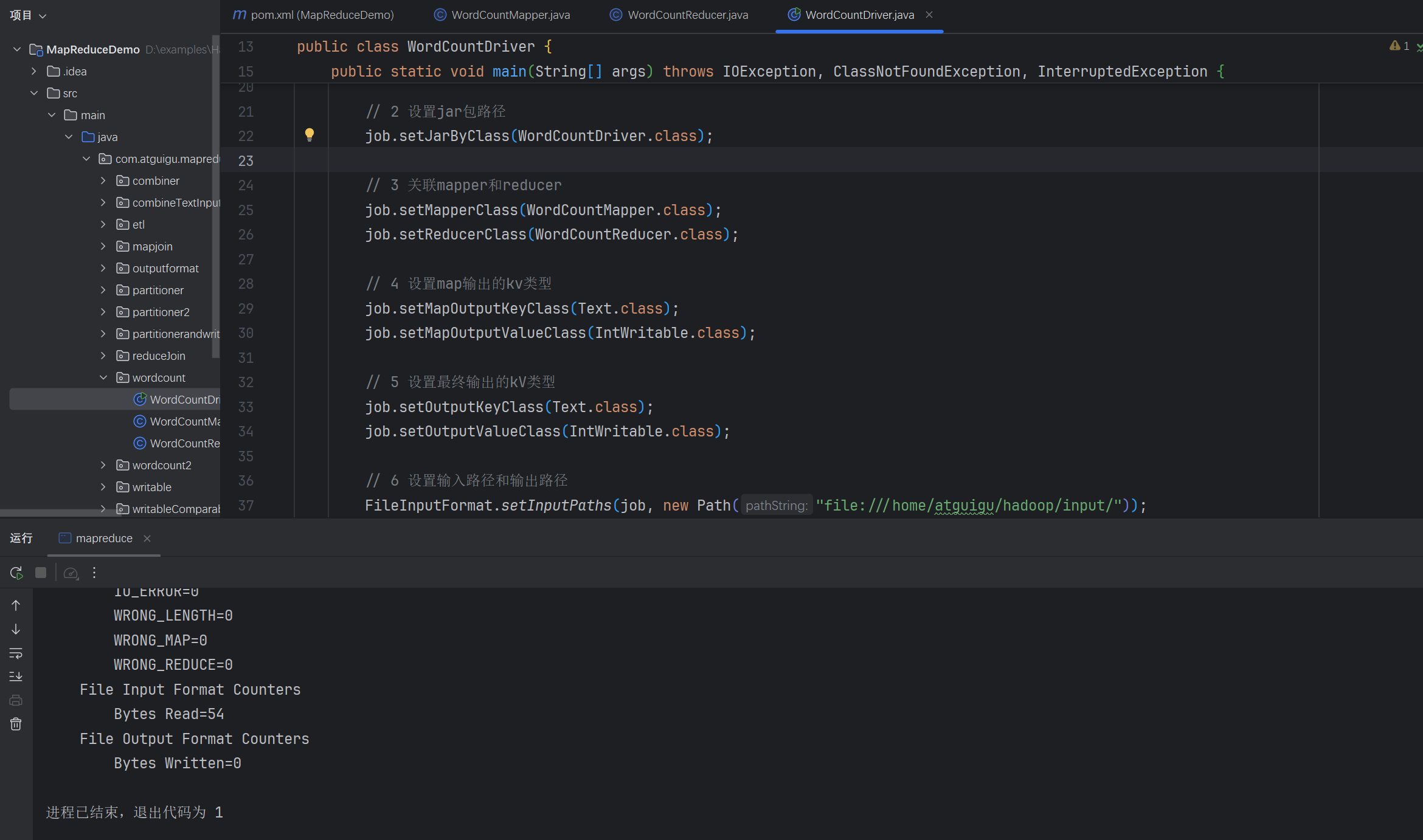
查看运行结果:
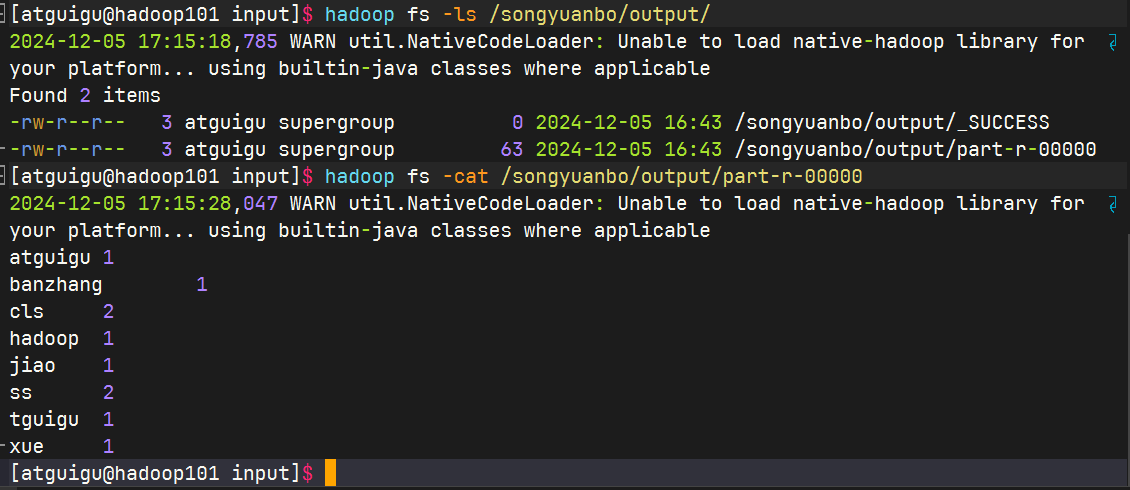
结果分词正确
如果需要调试应用和本地调试一样,打断点然后调试运行
提交集群测试
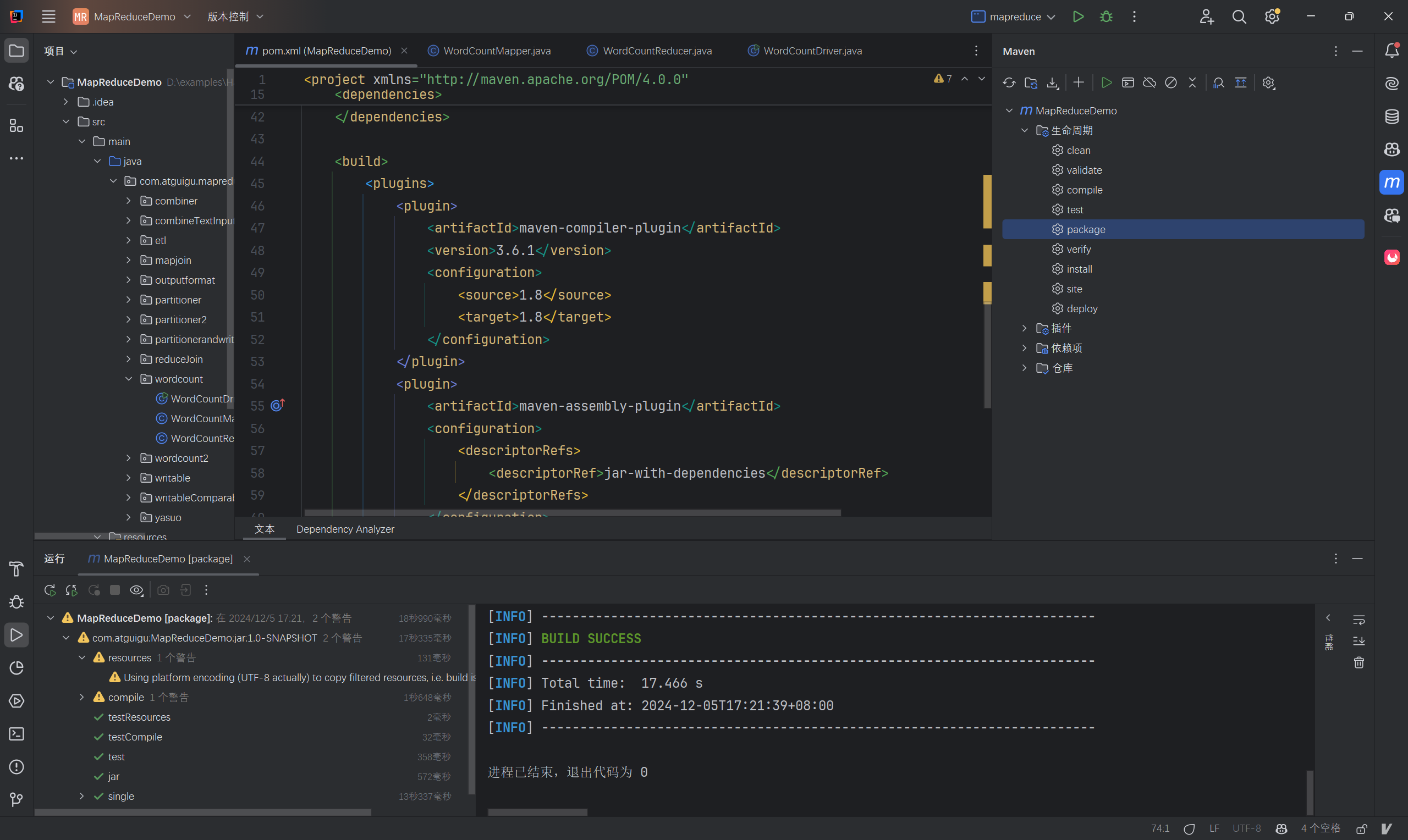
用maven打jar包,需要添加的打包插件依赖
<build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>将其添加到依赖中
将程序打成jar包
修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群的 /opt/module/hadoop-3.4.1路径。

启动Hadoop集群
bashmyhadoop start # 一键启动脚本执行WordCount程序
由于分布式部署与本地运行有区别所以编译是更改了文件输入路径
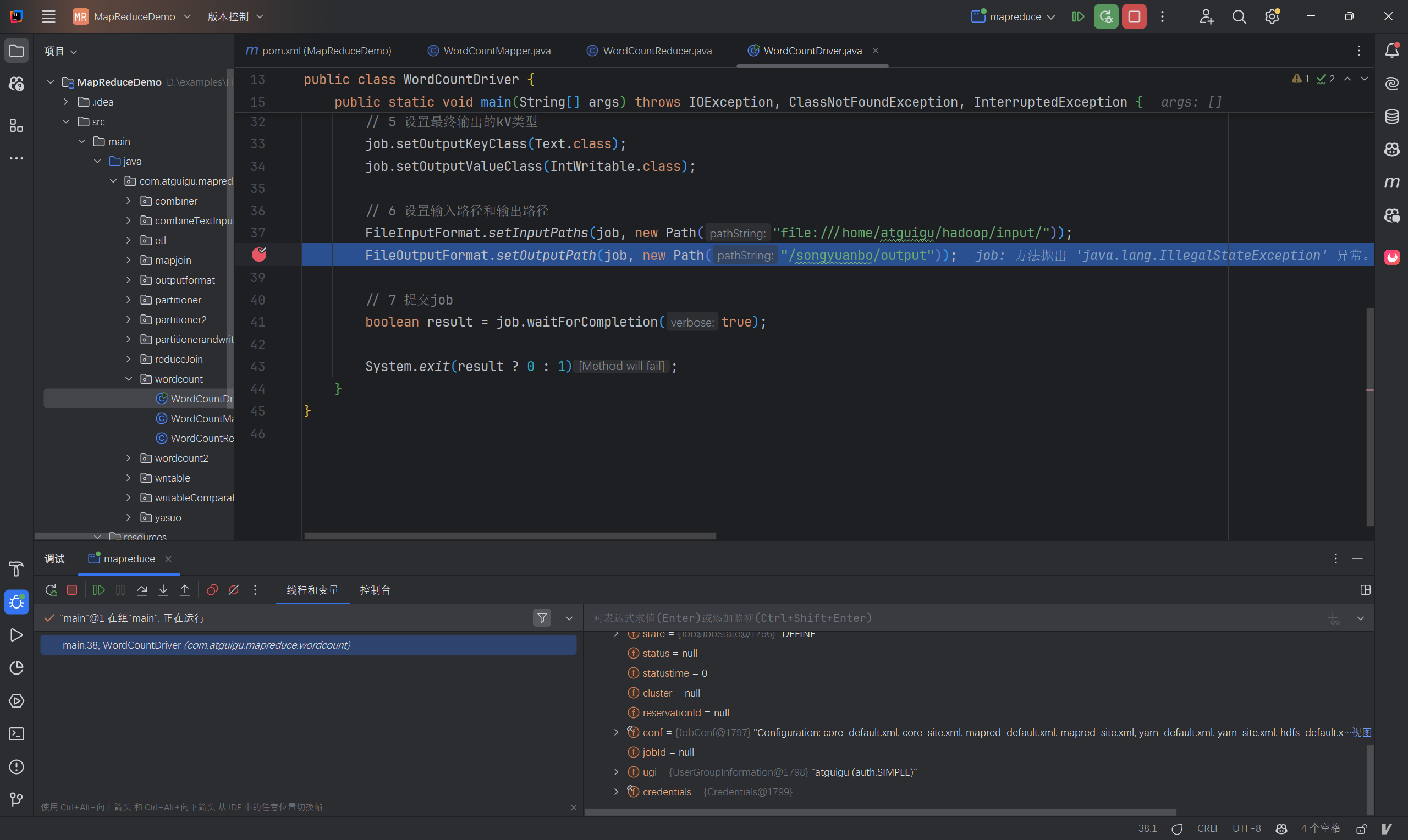
java// 6 设置输入路径和输出路径 FileInputFormat.setInputPaths(job, new Path("/songyuanbo/input/hello.txt")); FileOutputFormat.setOutputPath(job, new Path("/songyuanbo/output"));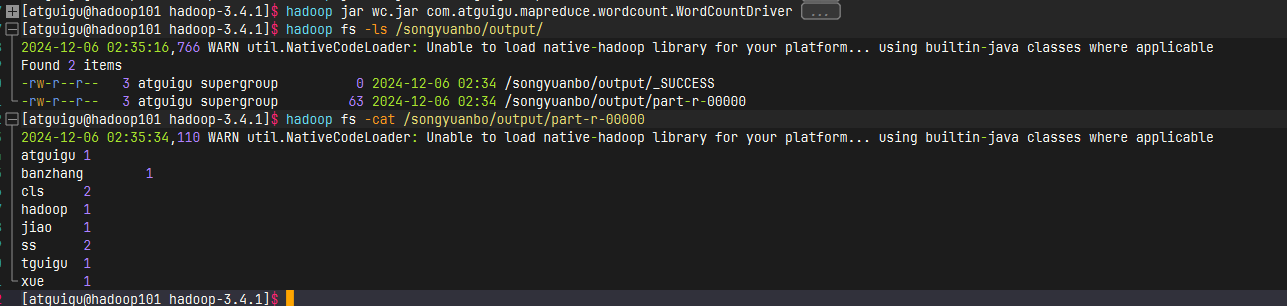
3. ReduceJoin案例
数据准备
查阅代码可知分类的标准是
\t,故此为要求编辑文件编辑order.txt
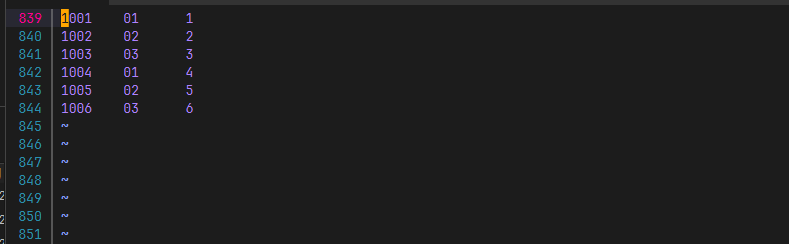
编辑pd.txt

上传到hdfs中方便之后集群运行
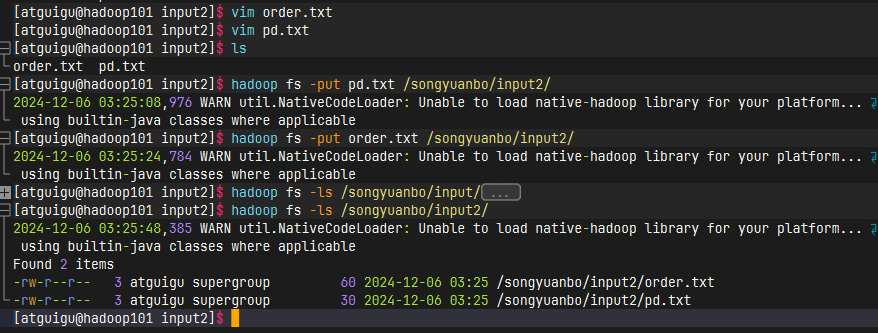
代码实现
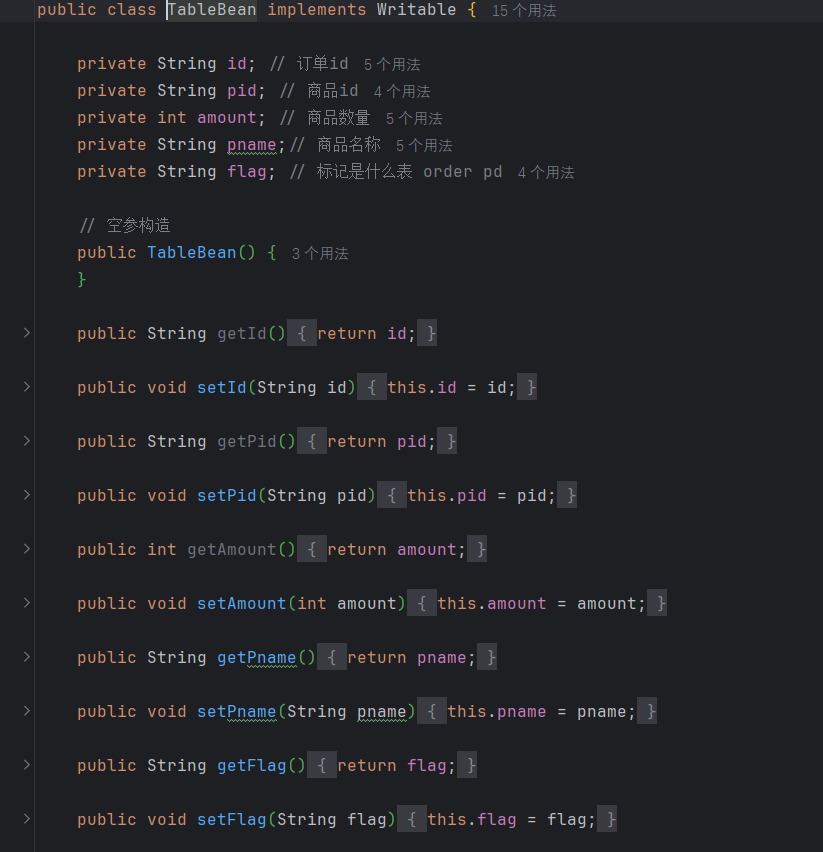
(1)创建商品和订单合并后的TableBean类(代码过长,简要展示)
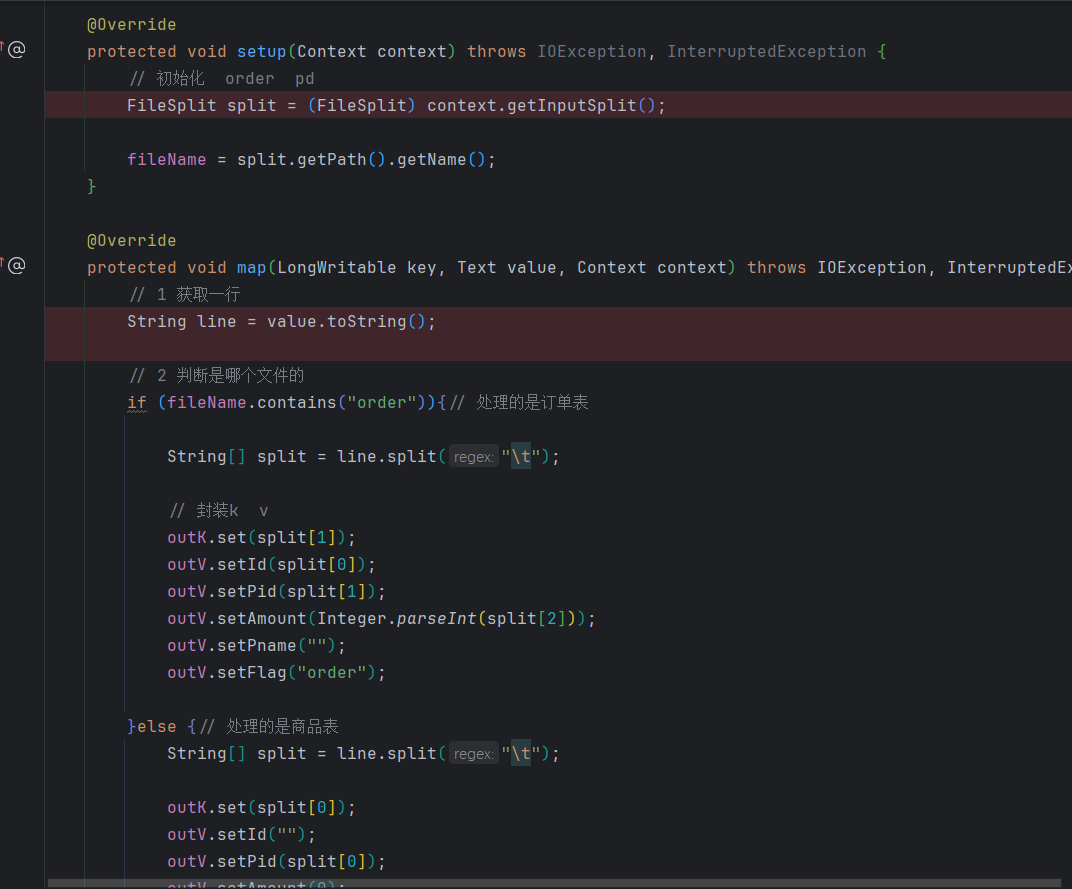
(2)编写TableMapper类(代码过长,简要展示)
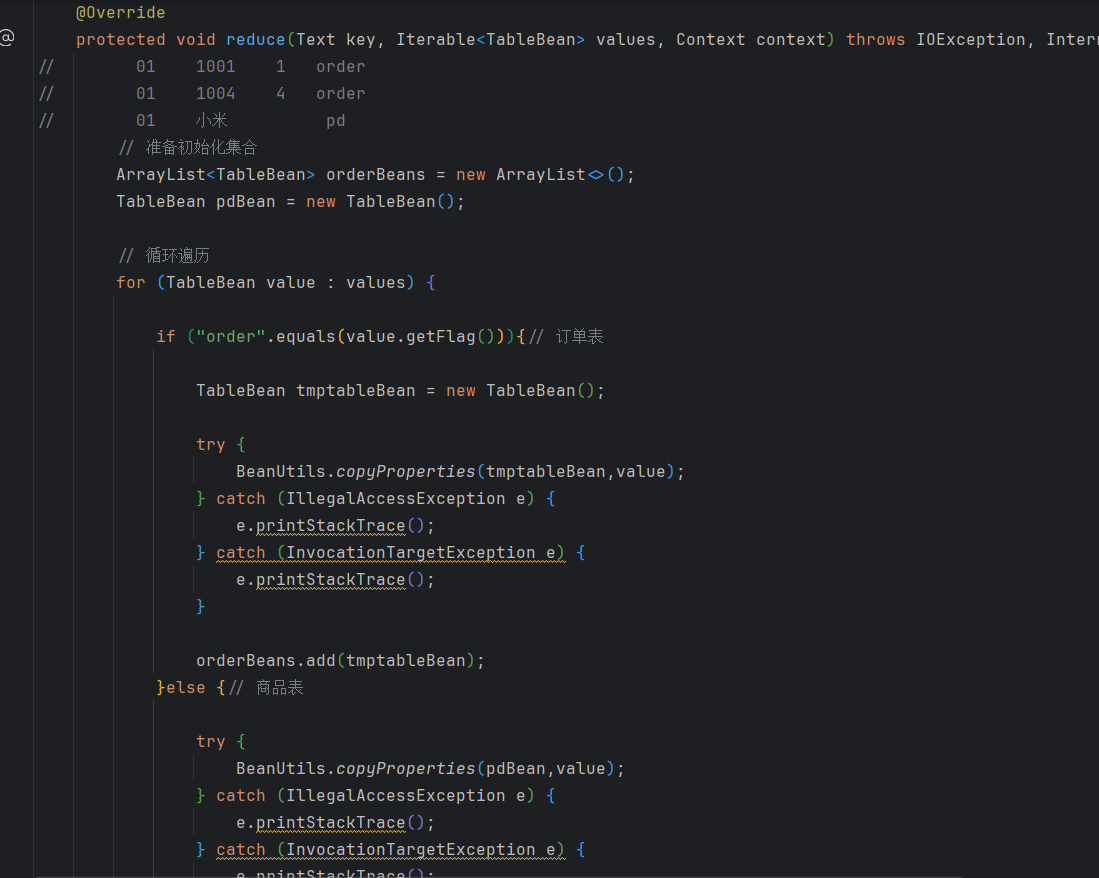
(3)编写TableReducer类(代码过长,简要展示)
(4)编写TableDriver类
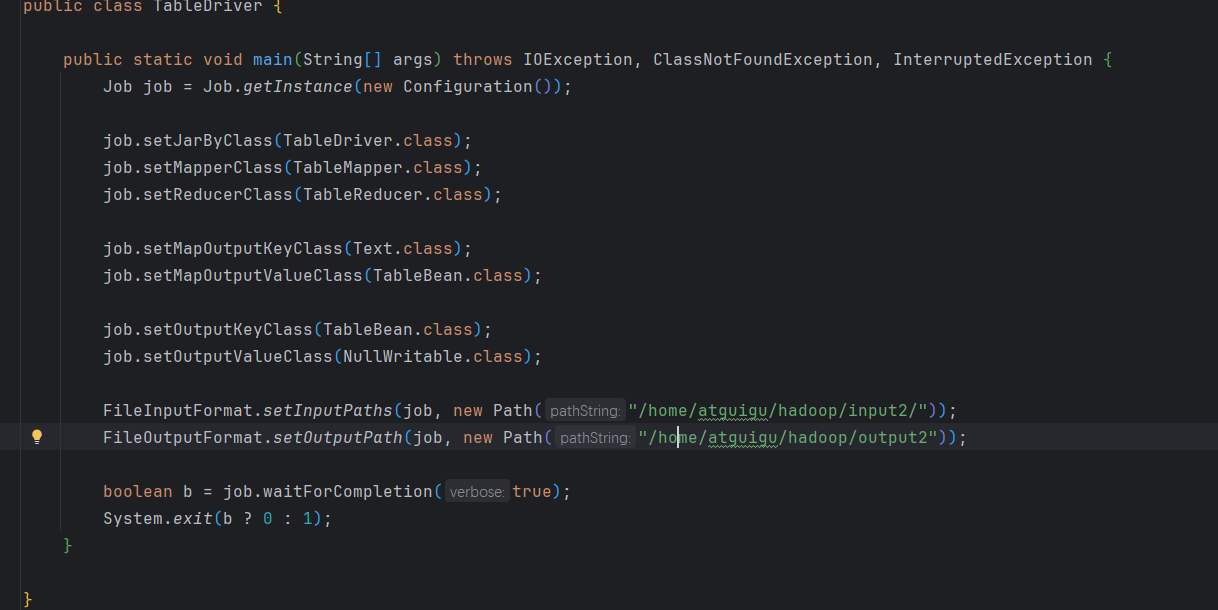
测试
运行程序

查看结果
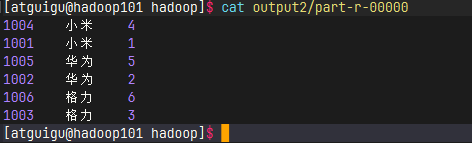
集群到部署
编译jar包然后上传到虚拟机
此处更改了输入输出文件路径
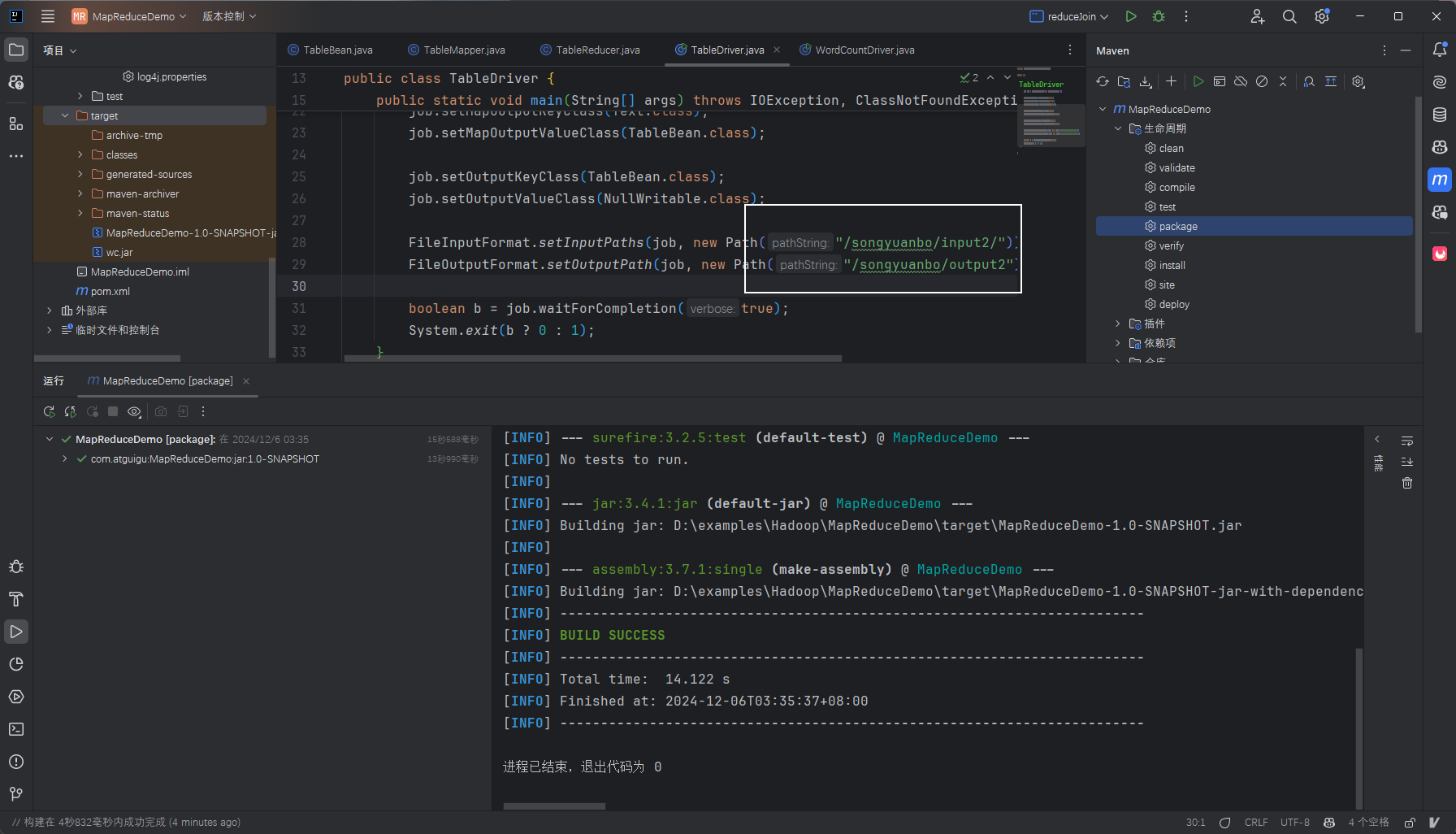
虚拟机中

运行程序
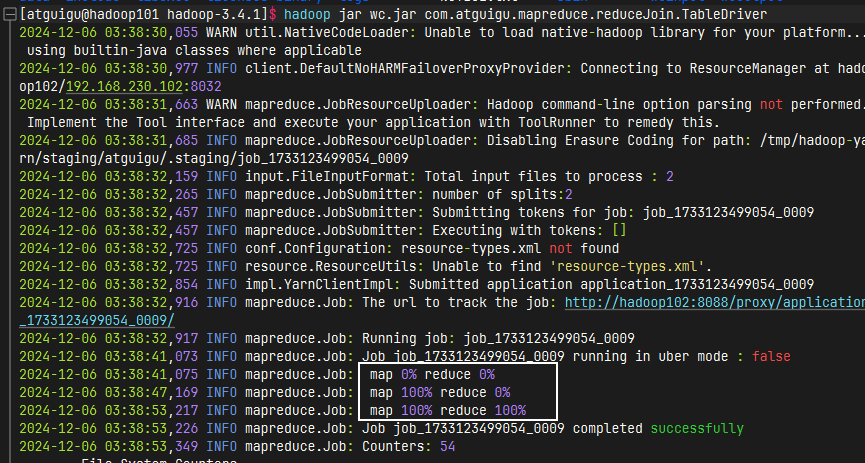 运行成功查看数据
运行成功查看数据 
四、总结
如何对mapreduce进行调试 ?
使用idea自带工具进行远程调试,原理大概是在windows上编译完成程序后会将文件上传到虚拟机中,使用虚拟机的java环境进行程序运行和调试,然后同步反馈在windows上。达到跟本地调试一样的调试体验。且windows不需要配置任何hadoop环境
如何解决三张表的连接操作,例如学生选课表。
例如在添加一张价格表,TableReducer.java中循环遍历中新增一个else if用于判断三张不同的表, 然后新增一个priceBean用于连接表,最后进行合并。当然 TableReducer.java里也要新增一个else if判断用于读取新的数据内容。
大概类似于这样
for (TableBean value : values) {
if ("order".equals(value.getFlag())) { // 订单表
TableBean orderCopy = new TableBean();
try {
BeanUtils.copyProperties(orderCopy, value);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
orderBeans.add(orderCopy);
} else if ("pd".equals(value.getFlag())) { // 商品表
try {
BeanUtils.copyProperties(pdBean, value);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
} else if ("price".equals(value.getFlag())) { //价格表
try {
BeanUtils.copyProperties(priceBean, value);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
}
}
// 如果pdBean和studentBean都被赋值,则进行连接操作
for (TableBean orderBean : orderBeans) {
orderBean.setPname(pdBean.getPname()); // 设置商品名称
orderBean.setStudentName(priceBean.getpriceName()); // 设置商品价格
// 输出合并后的结果
context.write(orderBean, NullWritable.get());
}