本文最后更新于 4 年前,文中所描述的信息可能已发生改变。
Hadoop安装与配置
一、安装Hadoop
1.1 修改网络配置
在添加完虚拟主机后发现其网络地址与我的vmware的设置不同于是修改虚拟机的网段为230
运行ip addr指令显示地址
ip addr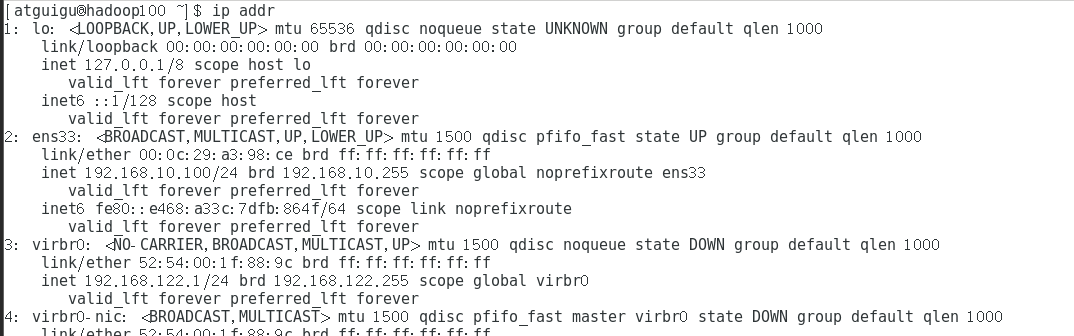
切换到/etc/sysconfig/network-scripts目录下
cd /etc/sysconfig/network-scripts然后编辑ifcfg-ens33用于修改IP地址
IPADDR=192.168.230.100 GATEWAY 192.168.230.2 DNS1=192.168.230.2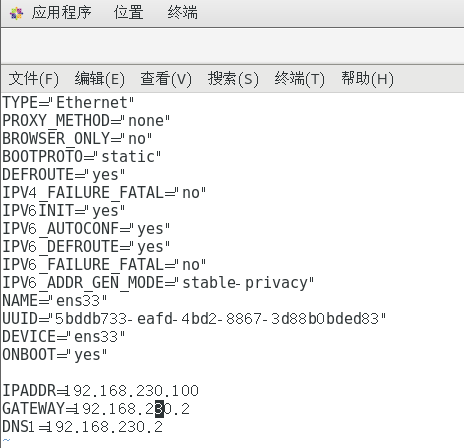
重启网卡并ping百度检测网络是否修正完成
shellsystemctl restart network ping www.baidu.com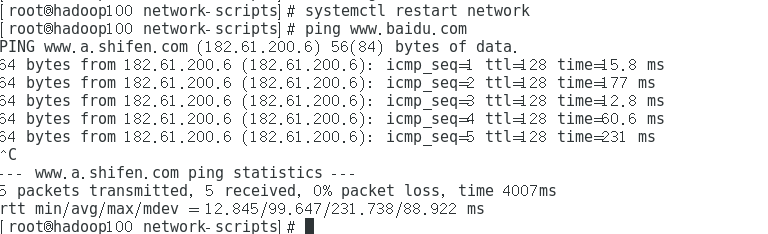
1.2 模板虚拟机环境准备
安装 epel-release
shellyum install -y net-tools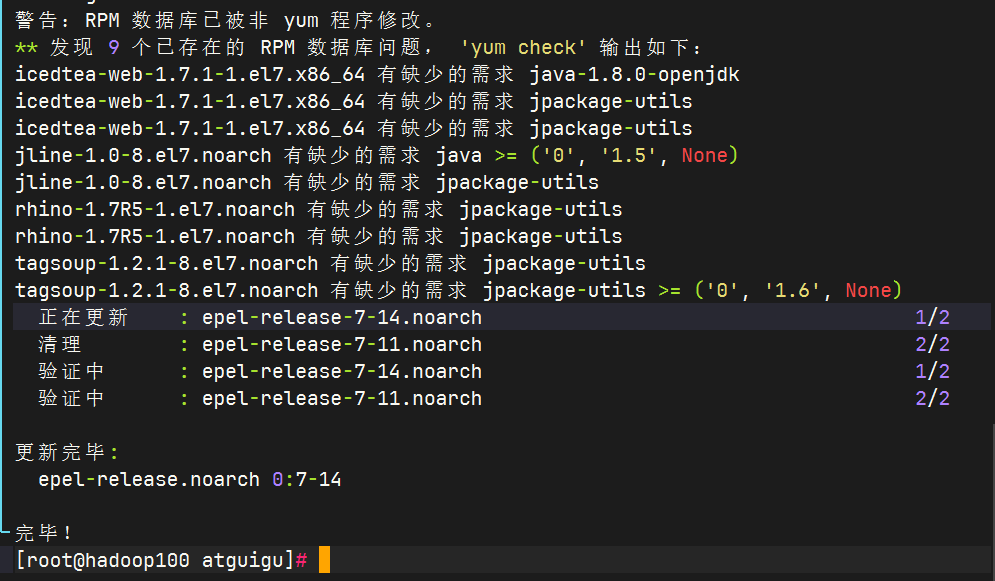
安装 net-tools
但是无镜像可以,猜测与centos停止维护有关尝试更换为国内镜像源

备份yum源文件
shellsudo cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak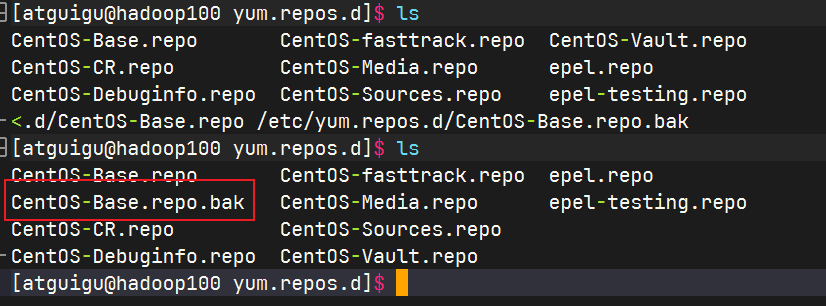
下载国内源
shellsudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo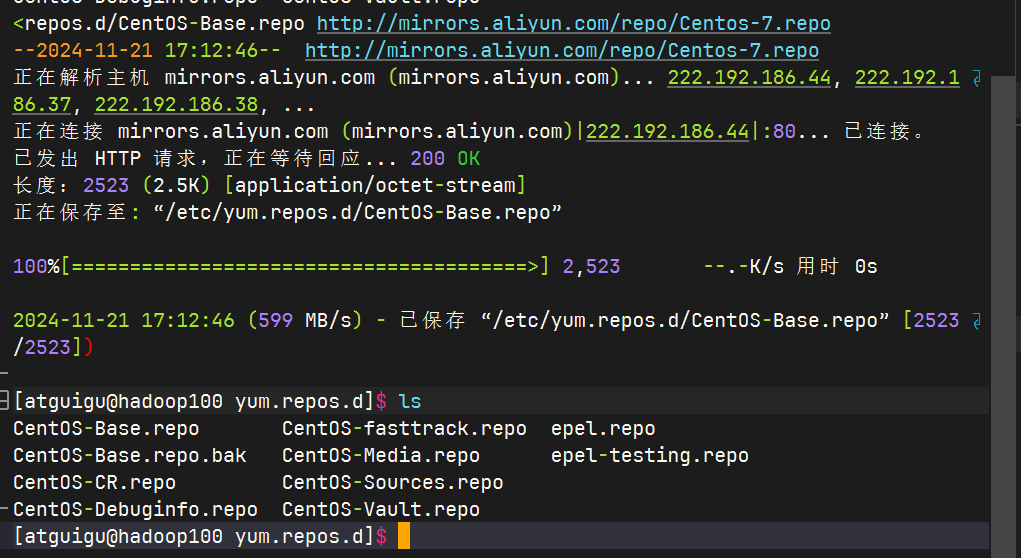
尝试重新下载
shellsudo yum install -y net-tools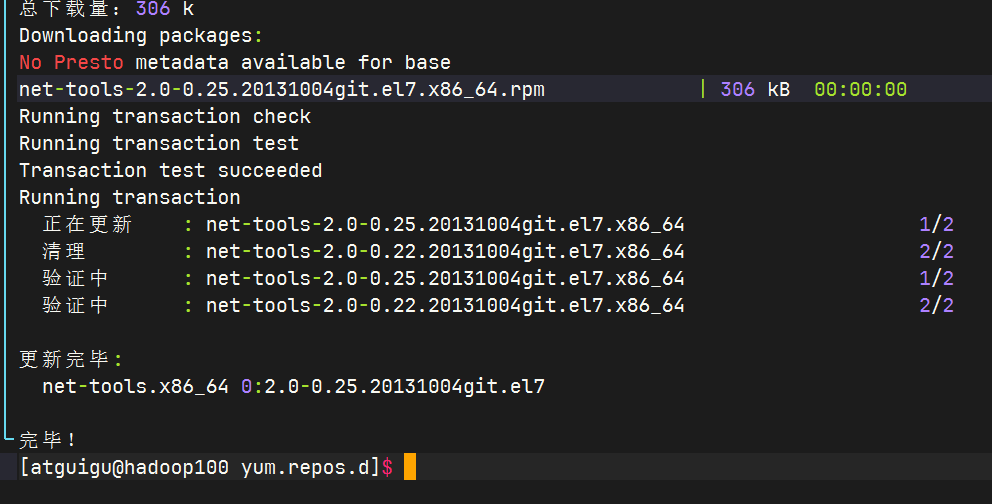
安装更新vim
shellsudo yum install -y vim
关闭防火墙
shellsystemctl stop firewalld systemctl disable firewalld.service
创建atguigu用户,并修改atguigu用户的密码
shell[root@hadoop100 ~]# useradd atguigu [root@hadoop100 ~]# passwd atguigu配置atguigu用户具有root权限,方便后期加sudo执行root权限的命令
vim /etc/sudoers修改/etc/sudoers 文件,在%wheel这行下面添加一行,如下所示:
## Allow root to run any commands anywhere root ALL=(ALL) ALL ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL在/opt目录下创建文件夹,并修改所属主和所属组
- 在/opt目录下创建module、software文件夹
- 修改module、software 文件夹的所有者和所属组均为atguigu用户
- 查看module、software 文件夹的所有者和所属组
卸载虚拟机自带的JDK
shellroot@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps重启虚拟机
shellreboot
1.3. 克隆虚拟机
使用模板主机克隆出三台虚拟机
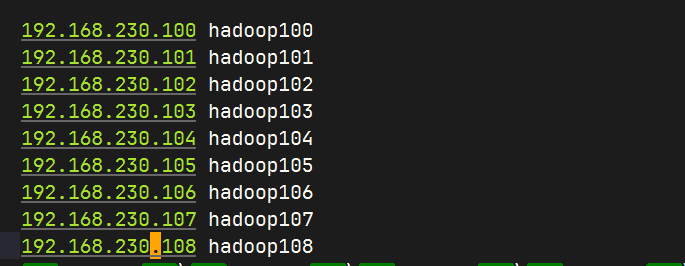
逐一修改克隆机的IP
shellvim /etc/sysconfig/network-scripts/ifcfg-ens33192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103修改hosts文件,将刚才的ip添加进去。
1.4 安装JDK
上传JDK压缩包
将JDK安装包移动到/opt/software

解压JDK到/opt/module
配置JDK环境变量
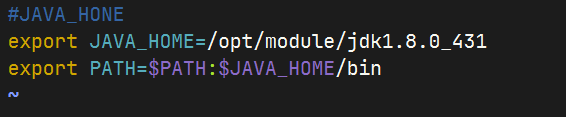
测试java安装是否成功
存在bug在配置完成java环境后依旧不能使用,经排查缺少glibc.i686,安装后即可使用
shellsudo yum install glibc.i686

1.5 安装Hadoop
下载导入
解压安装文件到/opt/module下面

查看是否解压成功
将Hadoop添加到环境变量
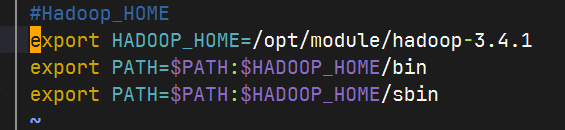
保存好,退出生效
查看是否生效
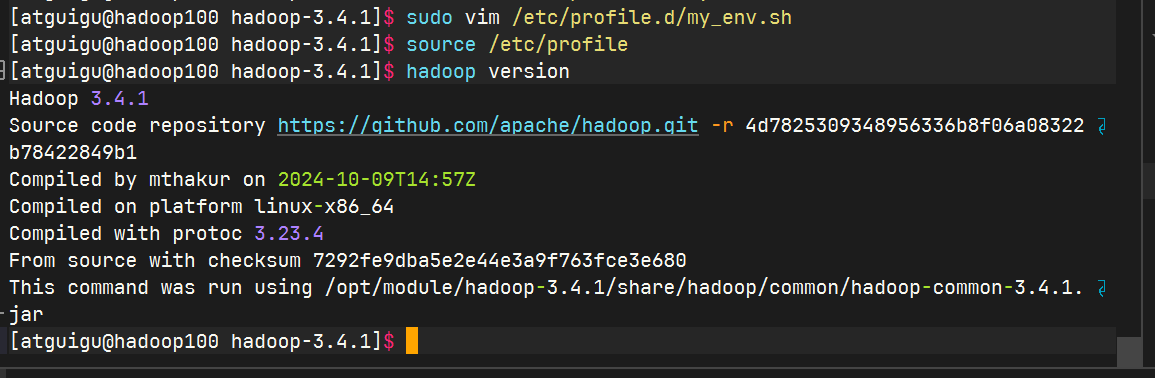
二、 Hadoop运行模式
2.1 本地运行(官方WordCount)
创建在hadoop-3.4.1文件下面创建一个wcinput文件夹

在wcinput文件下创建一个word.txt文件

编辑word.txt文件
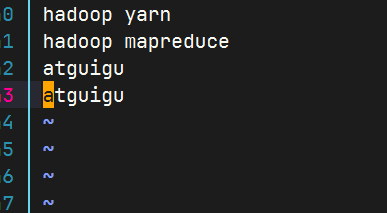
执行程序

查看结果
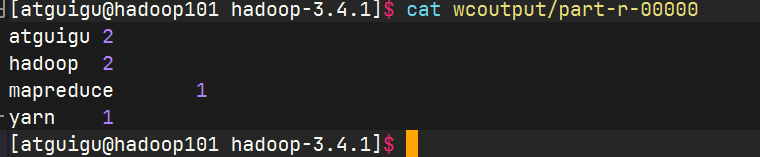
2.2 完全分布式运行模式
2.2.1 虚拟机准备
详见前面
2.2.2 编写集群分发脚本xsync
scp 安全拷贝
在hadoop101中将hadoop101中的jdk复制到hadoop102中
hadoop101中
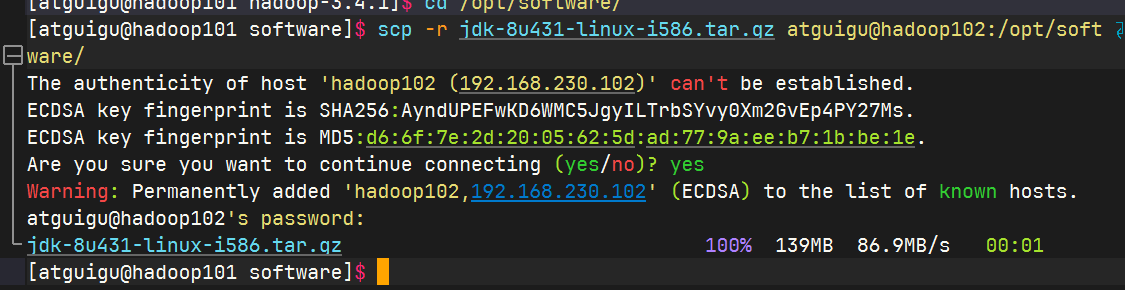
hadoop102中
在hadoop103中将hadoop101中的jdk复制到hadoop102中

在hadoop102中将hadoop101中的jdk复制到hadoop102中
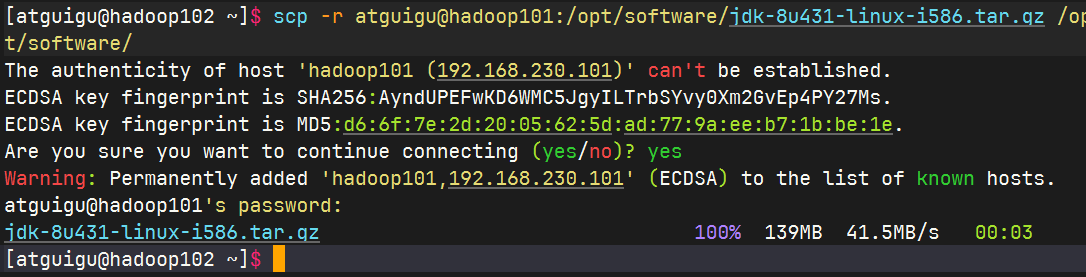
rsync 远程同步工具
删除hadoop102中的
/opt/module/hadoop-3.4.1/wcinput然后从hadoop101同步过去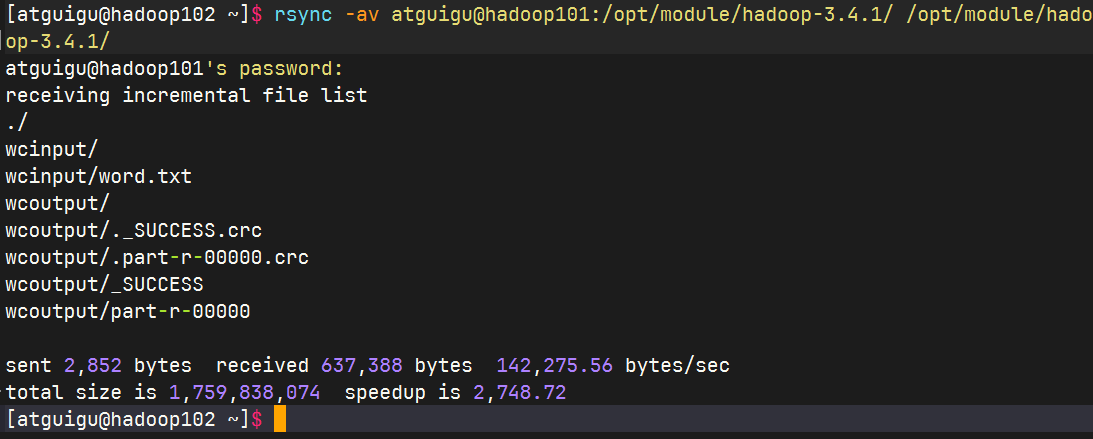
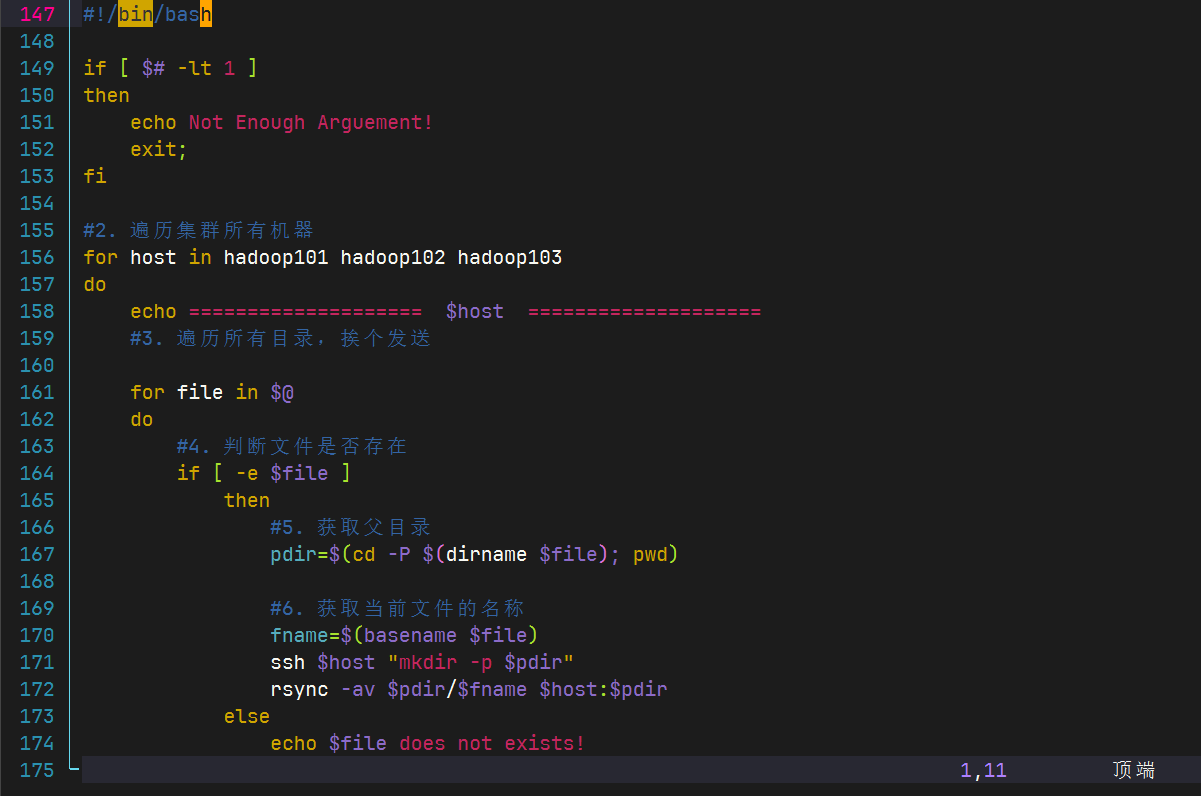
xsync 集群分发脚本
脚本实现
修改xsync的执行权限
测试脚本
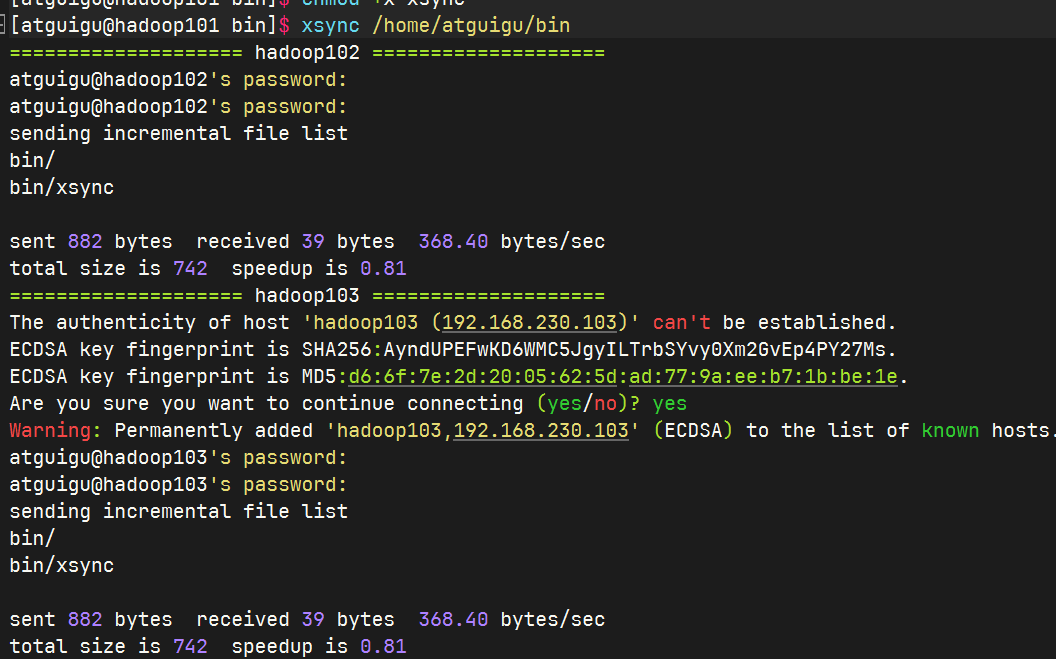
将脚本复制到/bin中,以便于全局调用

同步环境变量
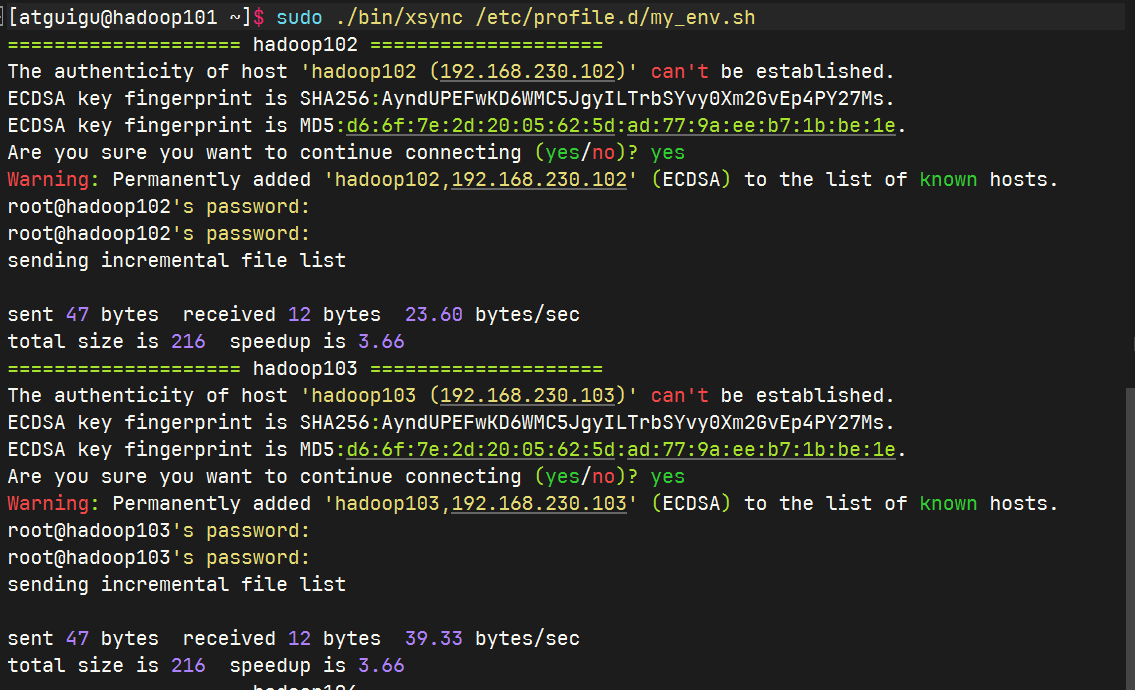
其他虚拟机生效环境变量
[atguigu@hadoop102 ~]$ source /etc/profile [atguigu@hadoop103 ~]$ source /etc/profile
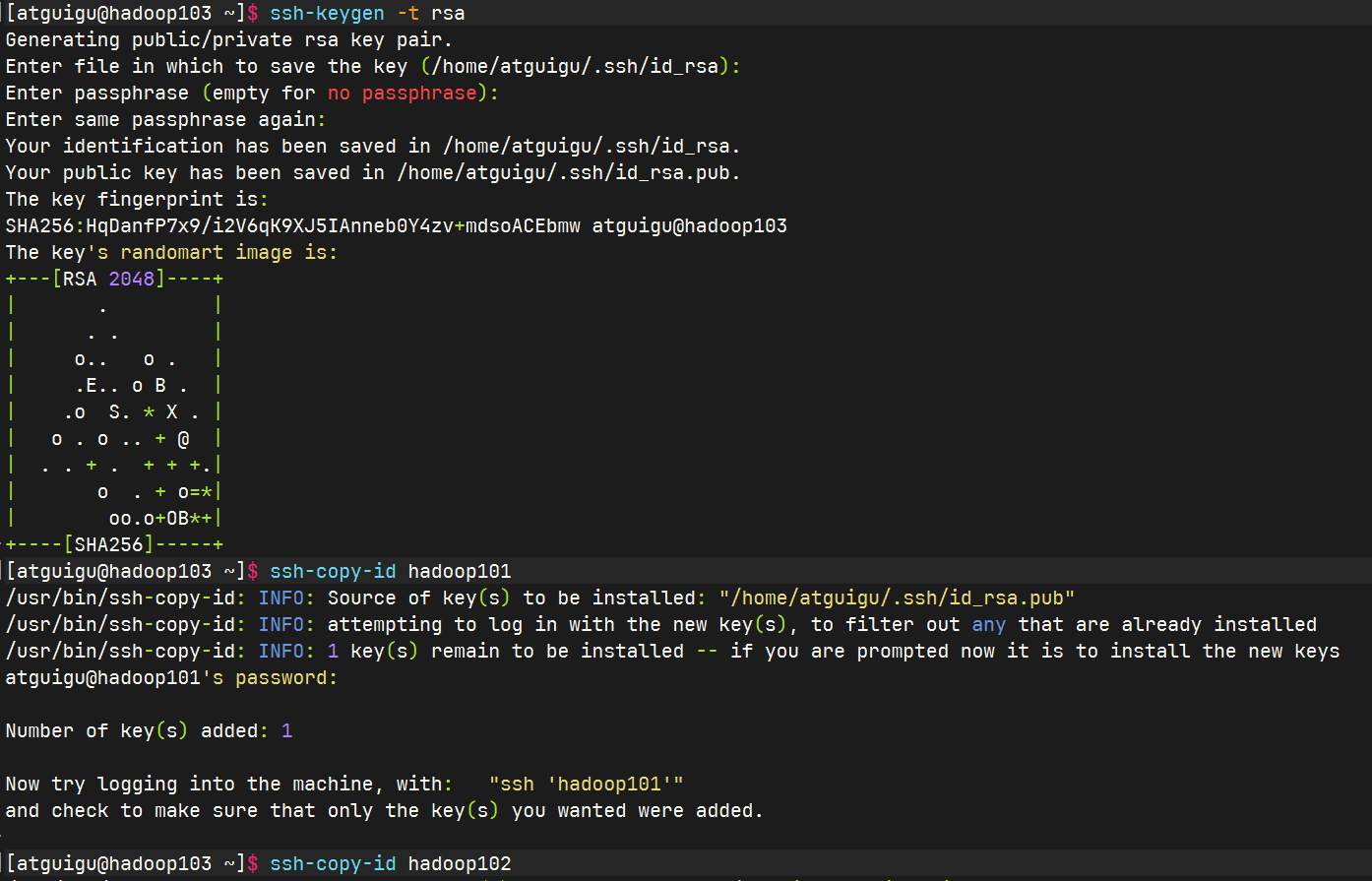
2.2.3 SSH无密登录配置
首先生成公钥和私钥,然后将公钥copy到需要免密登录的机器上去。
2.2.4 集群配置
配置集群
核心配置文件
配置
core-site.xmlshellcd /opt/module/hadoop-3.4.1/etc/hadoop vim core-site.xml内容如下
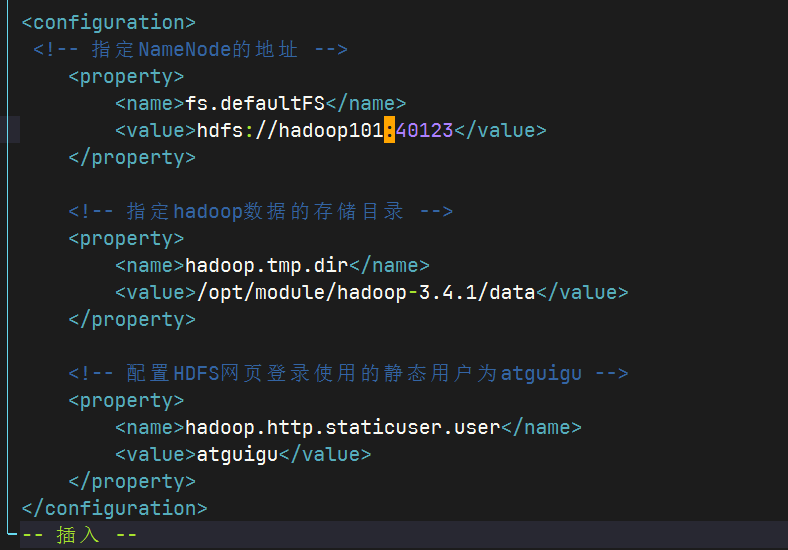
HDFS配置文件
vim hdfs-site.xml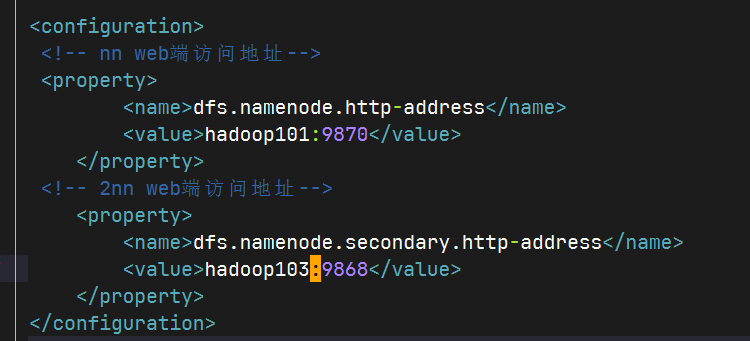
YRN配置文件
vim yarn-site.xml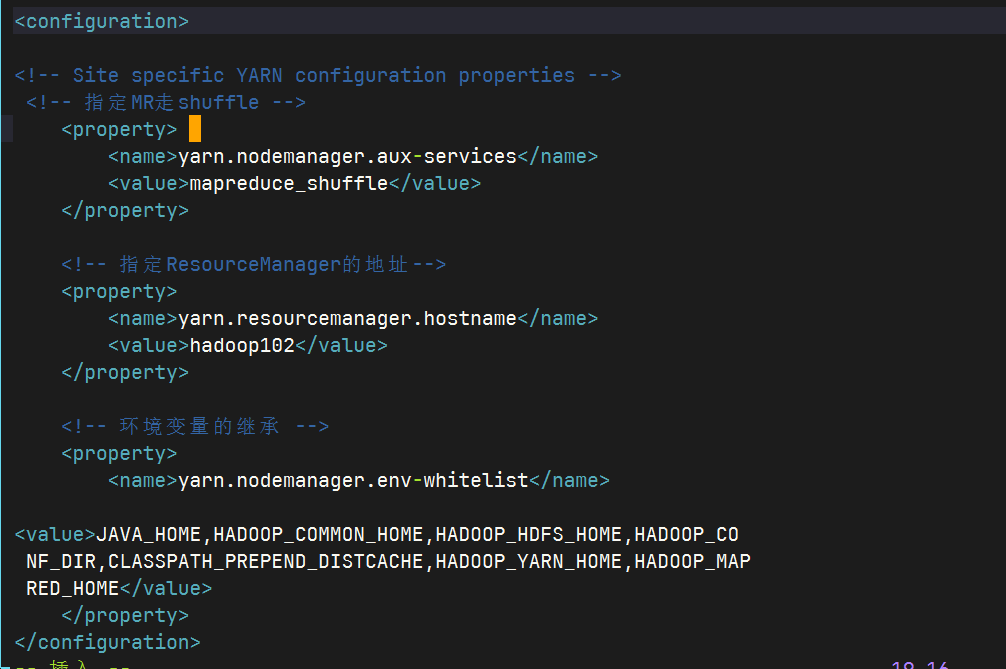
MapReduce配置文件
vim mapred-site.xml
在集群上分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-3.4.1/etc/hadoop/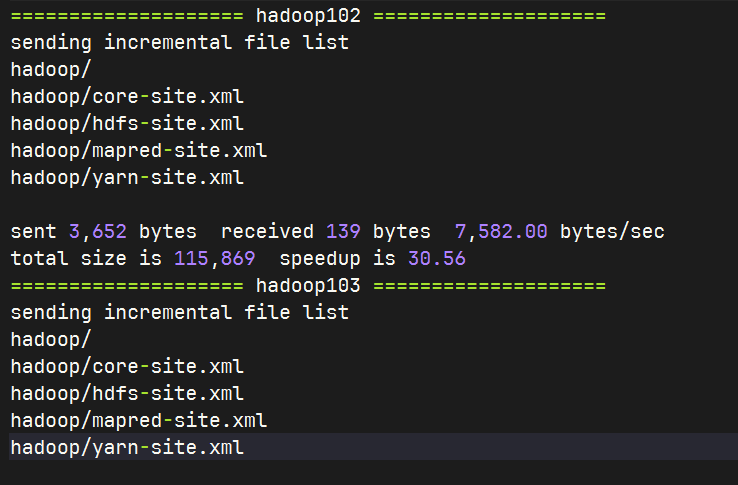
去102和103上查看文件分发情况
cat /opt/module/hadoop-3.4.1/etc/hadoop/core-site.xml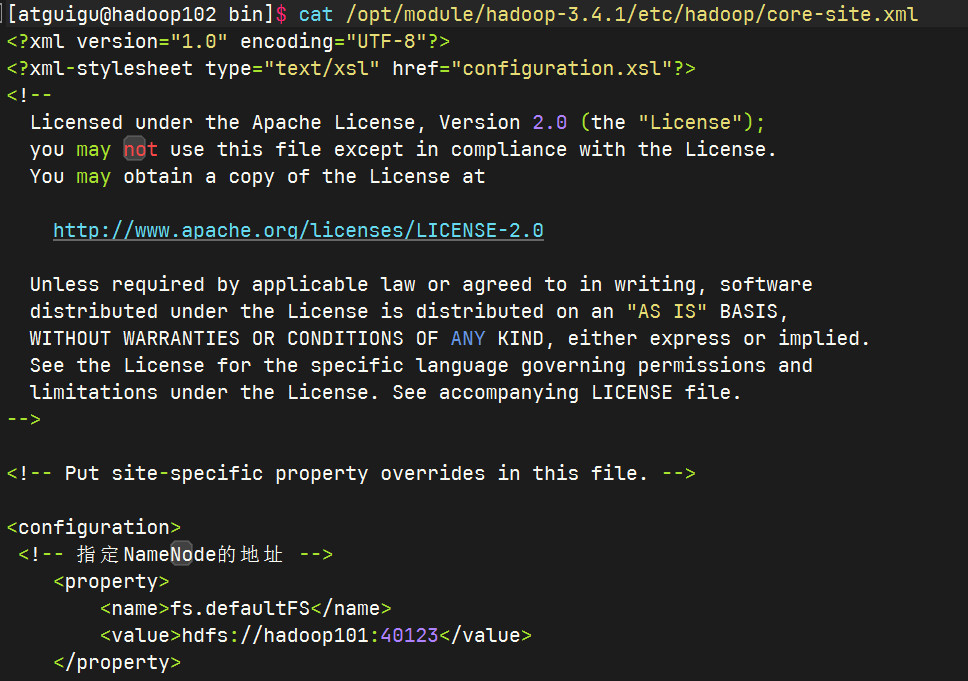
2.2.5 群起集群
配置workers
编辑workers文件
shellvim /opt/module/hadoop-3.4.1/etc/hadoop/workers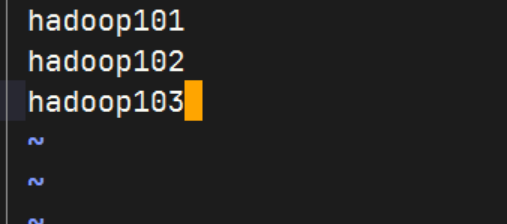
同步所以节点配置文件
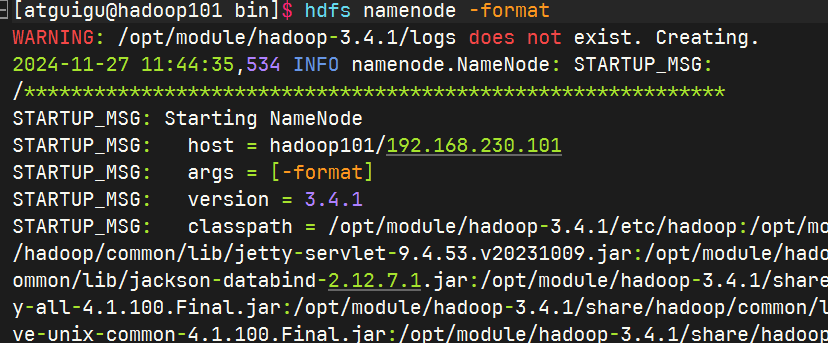
启动集群
格式化namenode
启动HDFS
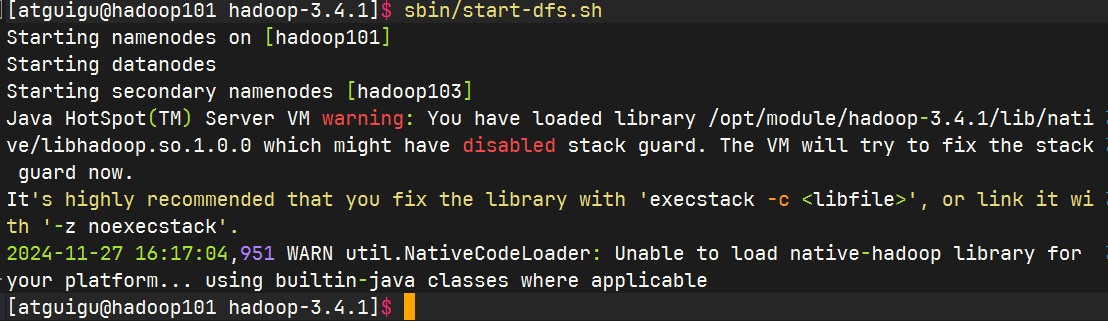
在配置了ResourceManager的节点(hadoop102)启动YARN

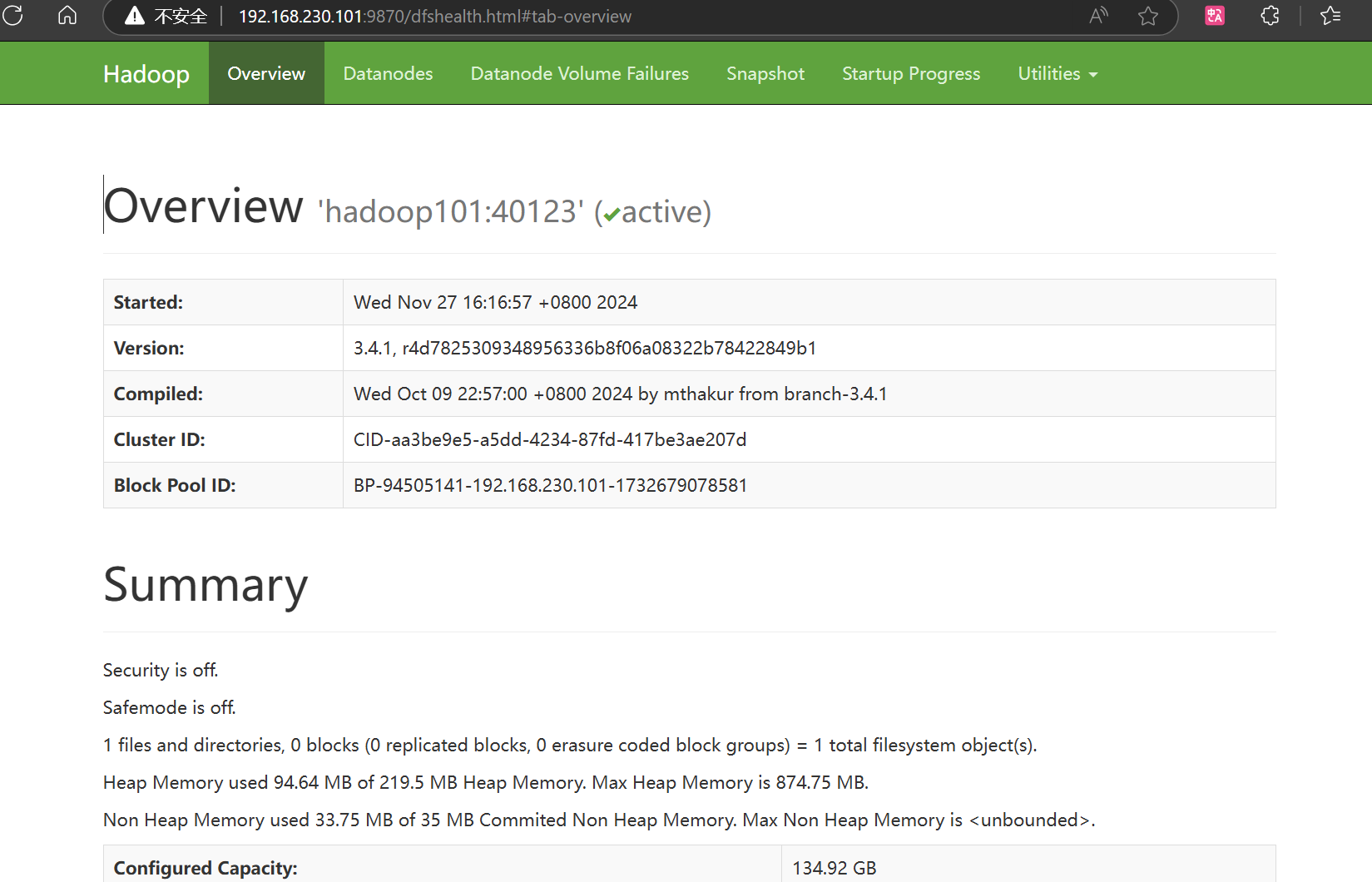
Web端查看HDFS的NameNode
Web端查看YARN的ResourceManager
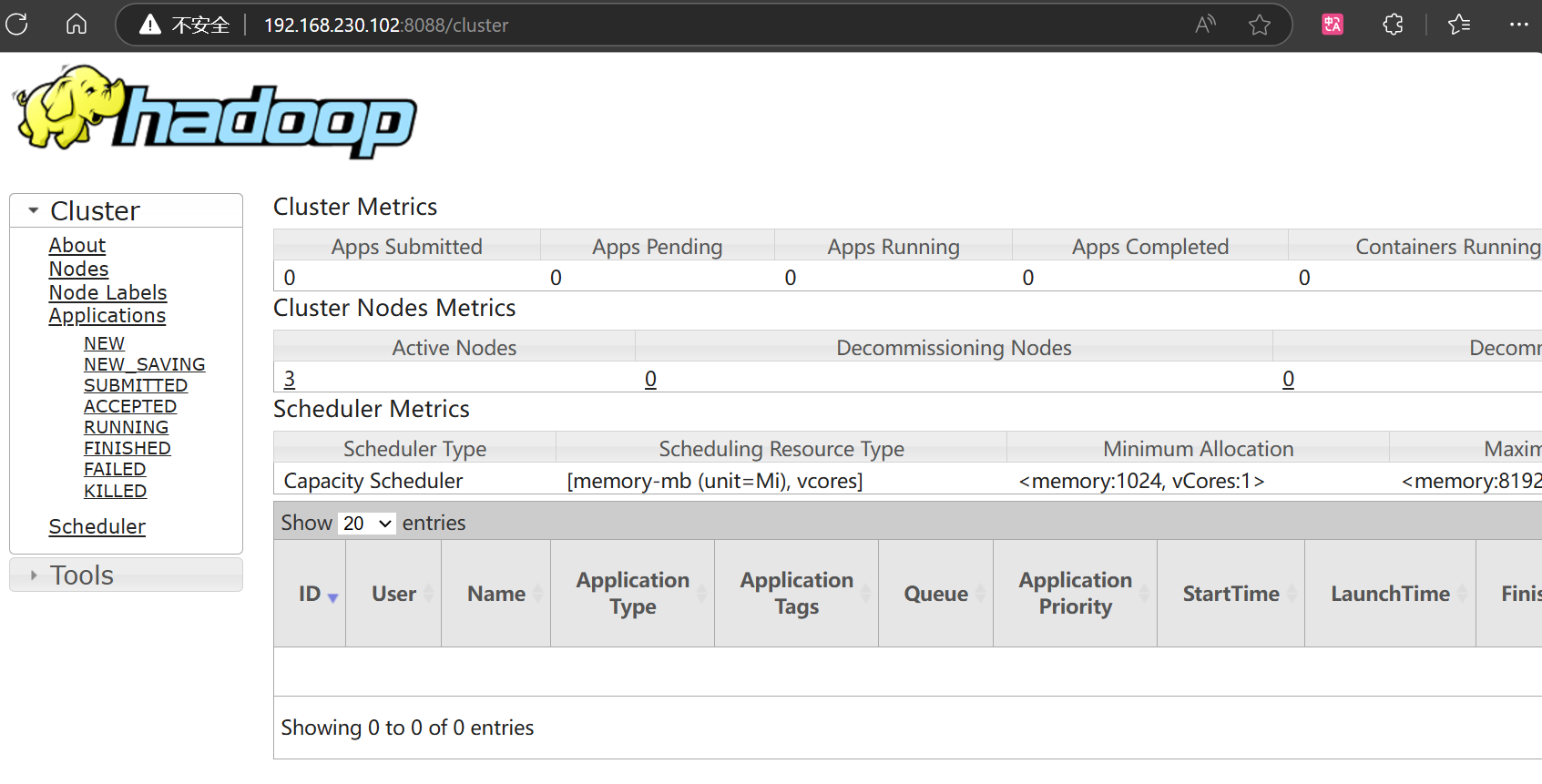
集群基本测试
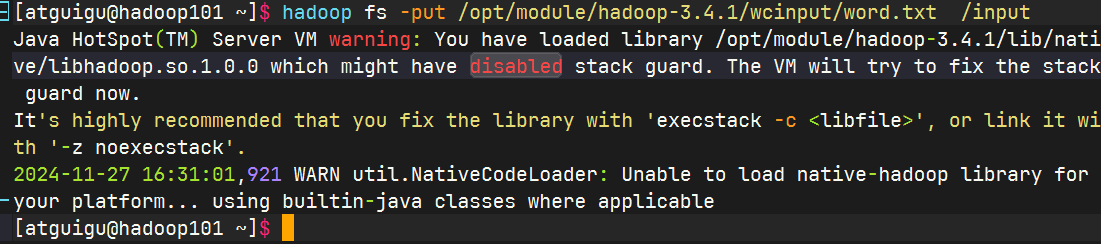
上传文件到集群
上传小文件

上传大文件
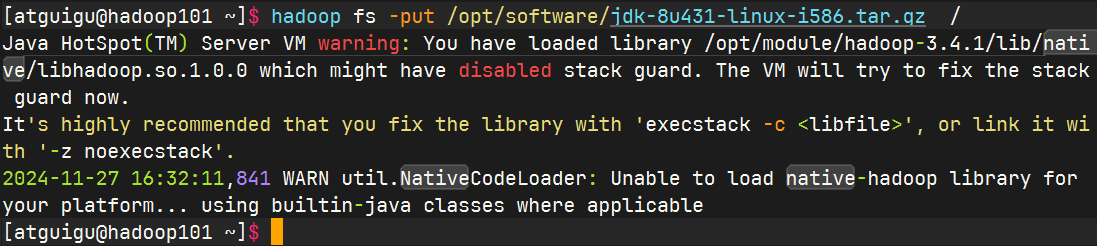
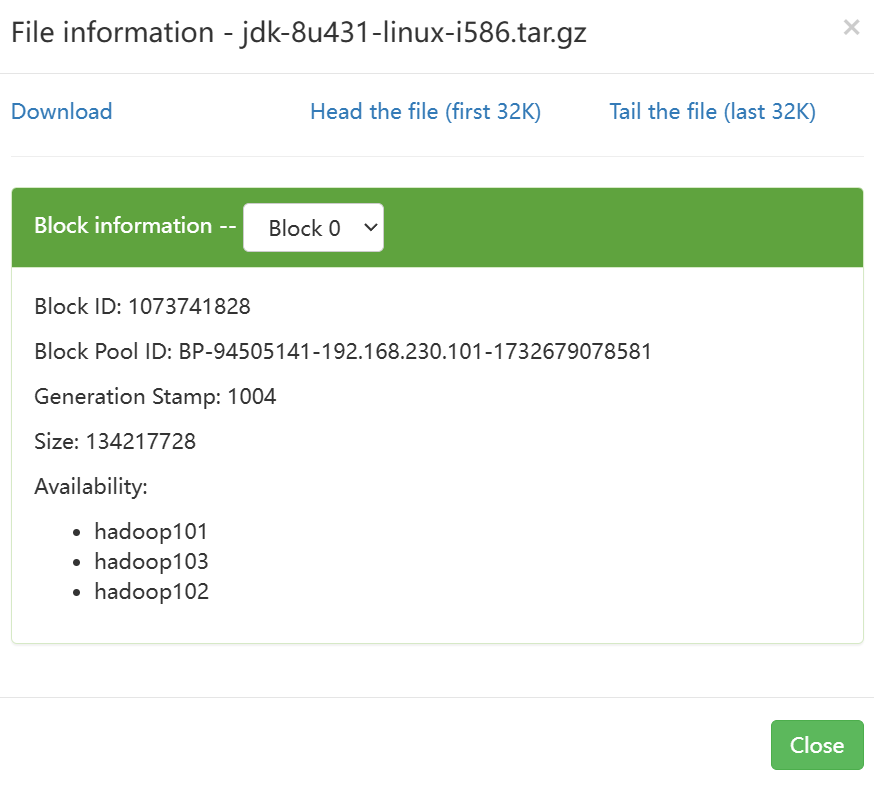
查看文件存放位置
根据block ID找到HDFS文件存储路径

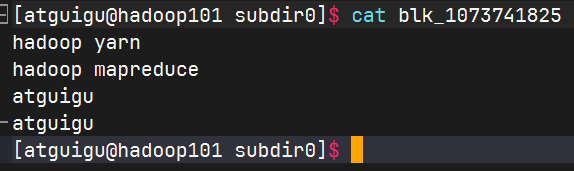
查看HDFS在磁盘存储文件内容
拼接
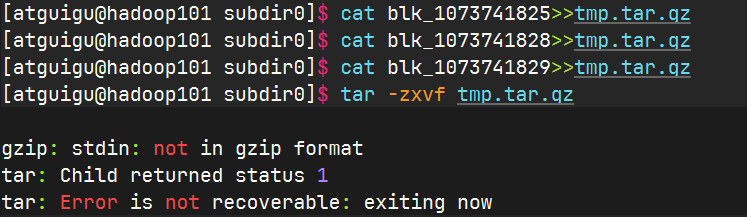
下载
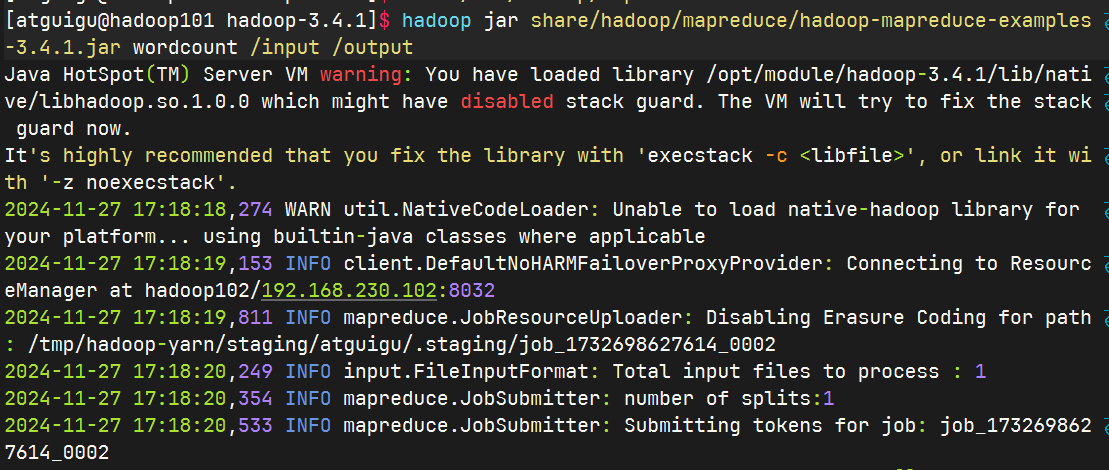
执行wordcount程序
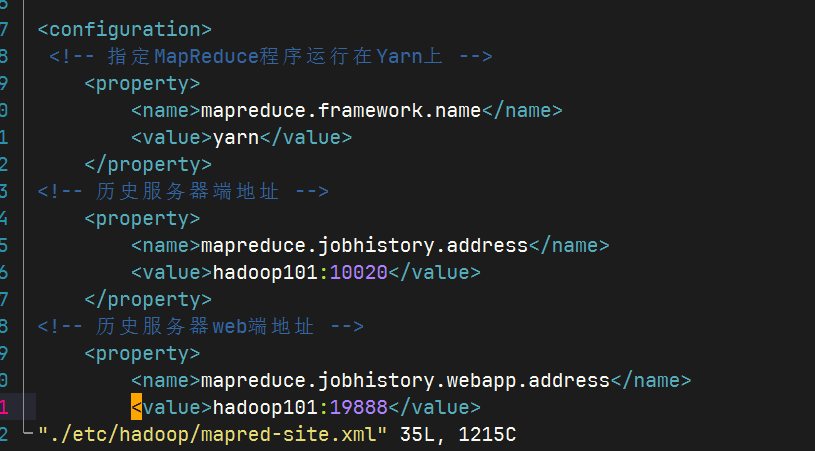
2.3.6 配置历史服务器
配置mapred-site.xml
分发配置
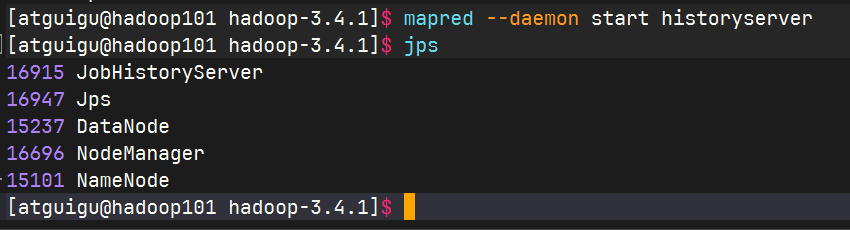
在hadoop102启动历史服务器
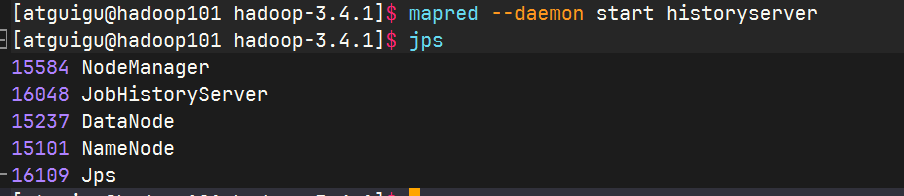
查看历史服务器是否启动
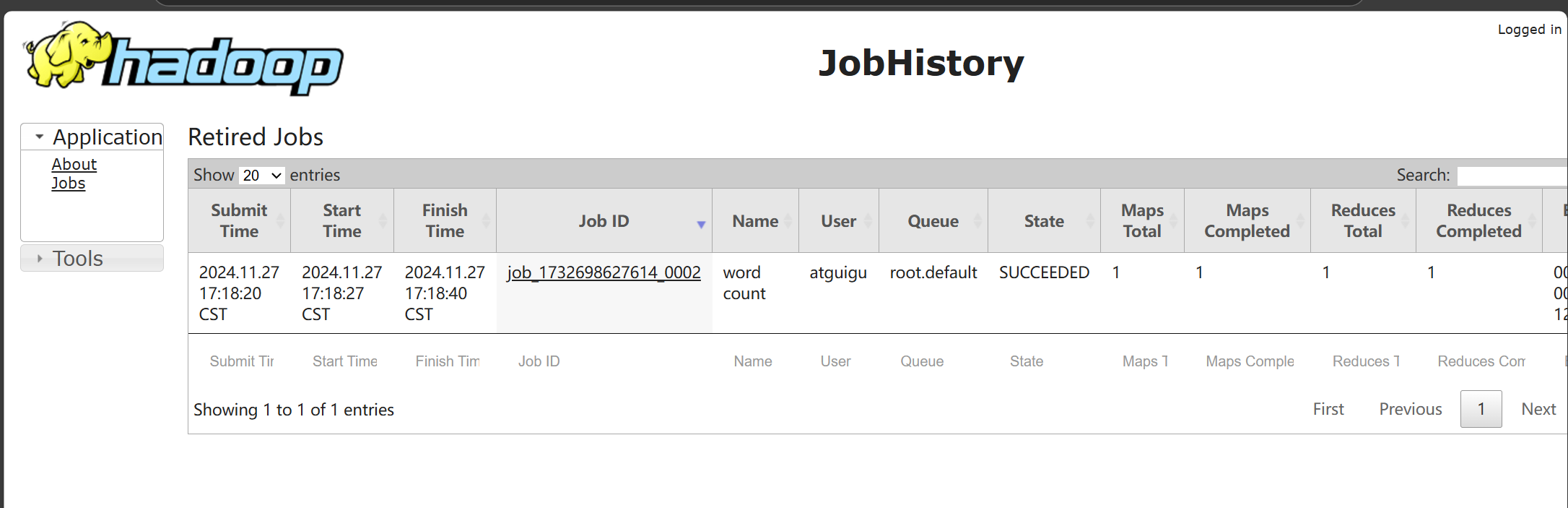
查看jobhistory
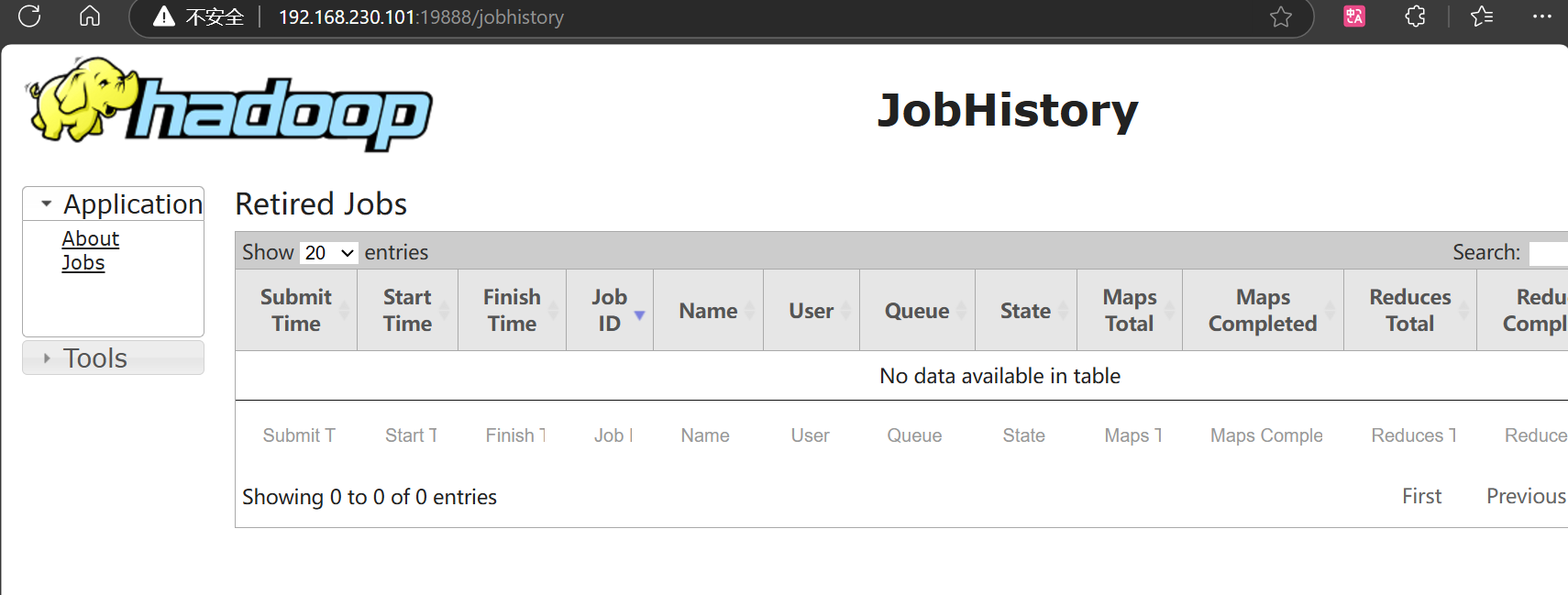
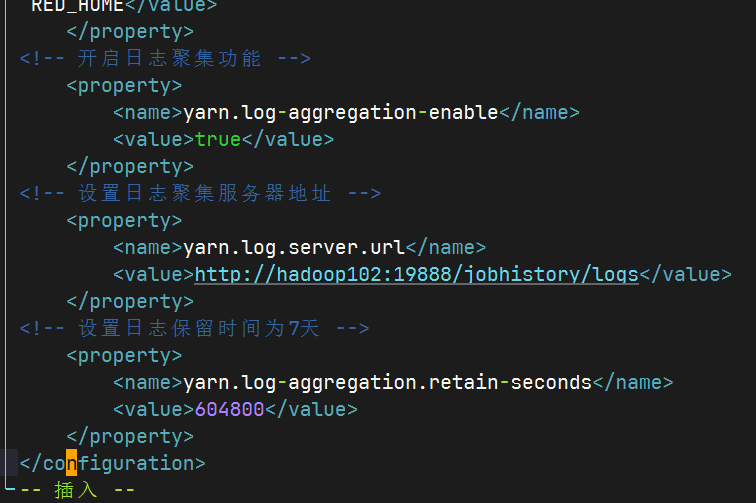
2.3.7配置日志的聚集
配置yarn-site.xml
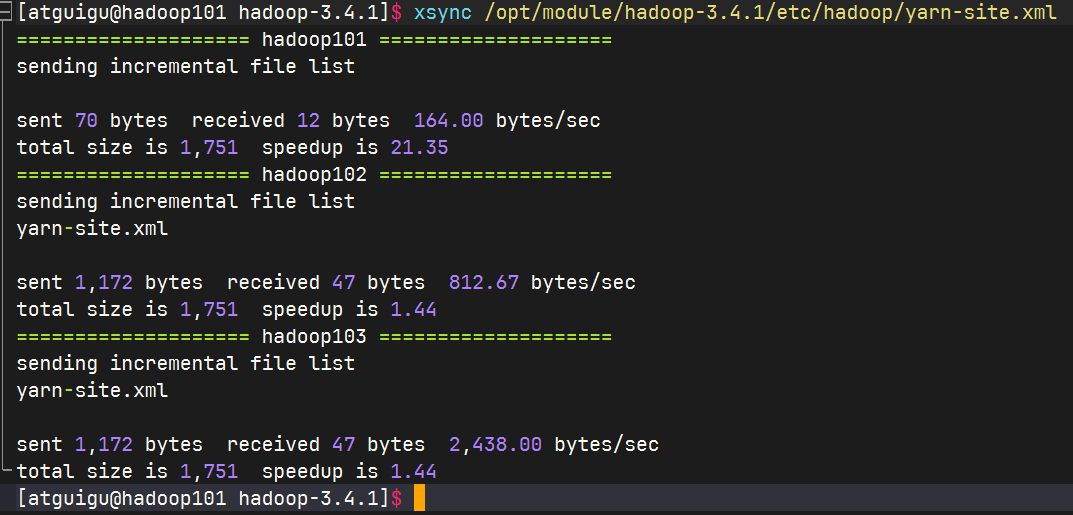
分发配置
关闭NodeManager 、ResourceManager和HistoryServer


启动NodeManager 、ResourceManager和HistoryServer

删除HDFS上已经存在的输出文件

执行WordCount程序
查看日志
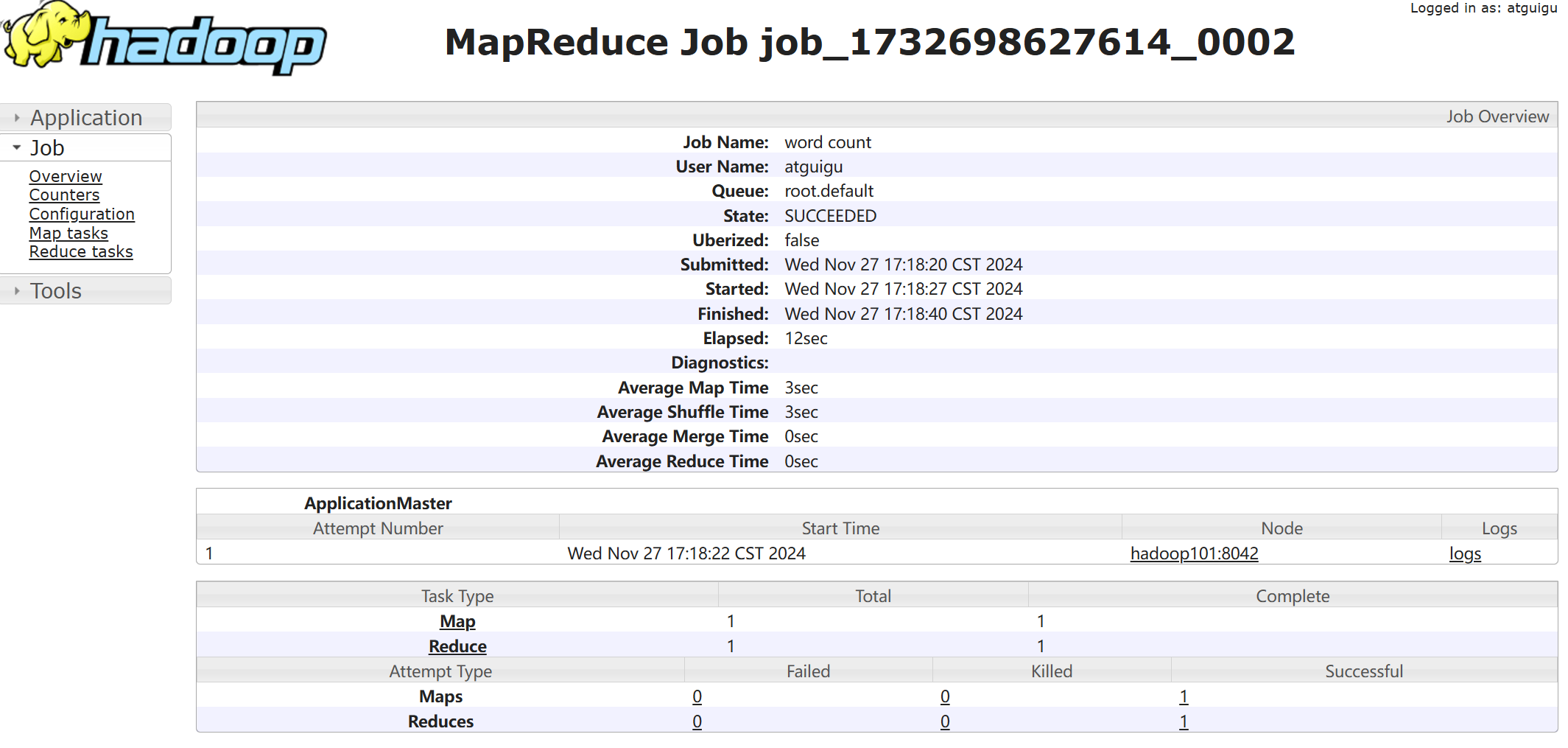
2.2.8 集群启动/停止方式总结
各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode(2)启动/停止YARNyarn --daemon start/stop resourcemanager/nodemanager
2.2.9 编写Hadoop集群常用脚本
- Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):
myhadoop.sh
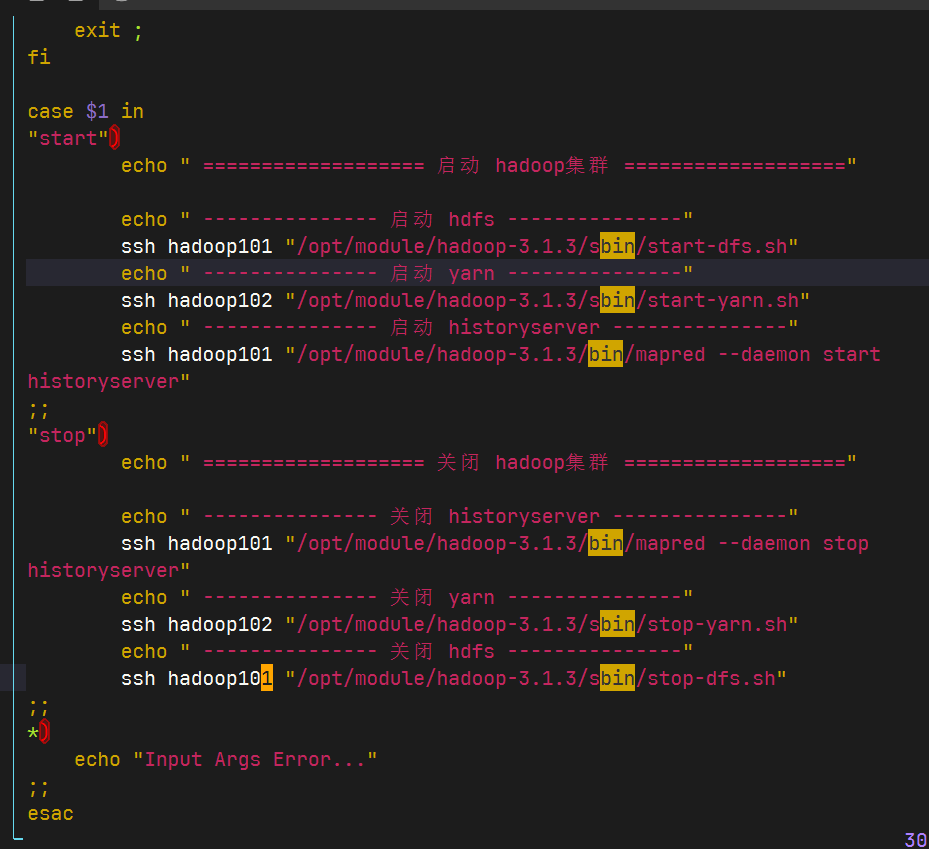
保存后退出赋予脚本执行权限

查看三台服务器Java进程脚本:jpsall
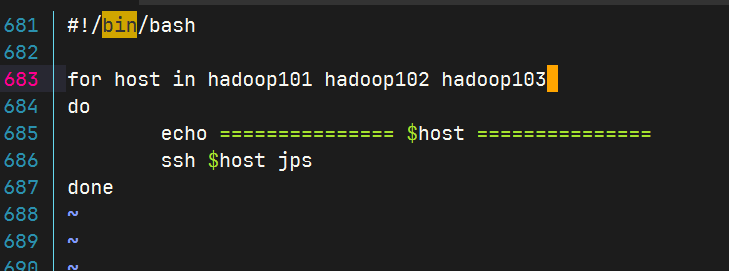
保存后退出赋予脚本执行权限

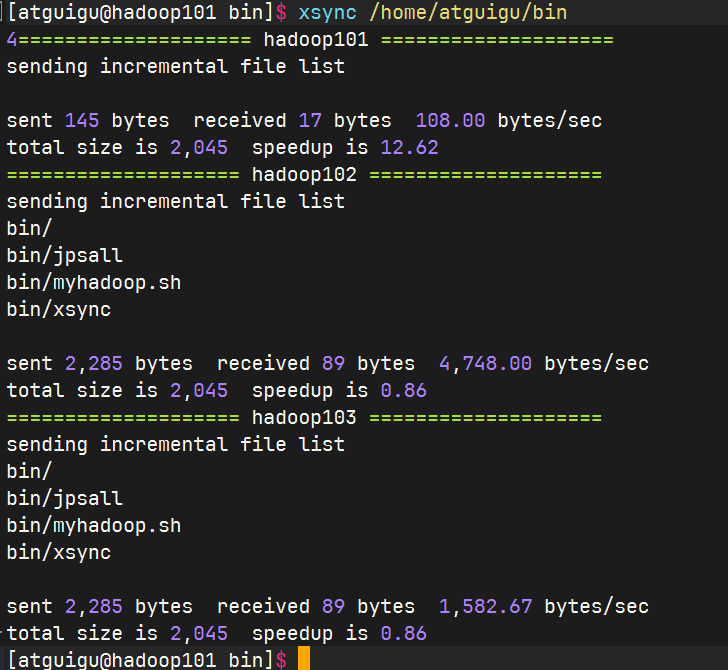
分发/home/atguigu/bin目录,保证自定义脚本在三台机器上都可以使用
2.2.10 常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
2.2.11 集群时间同步
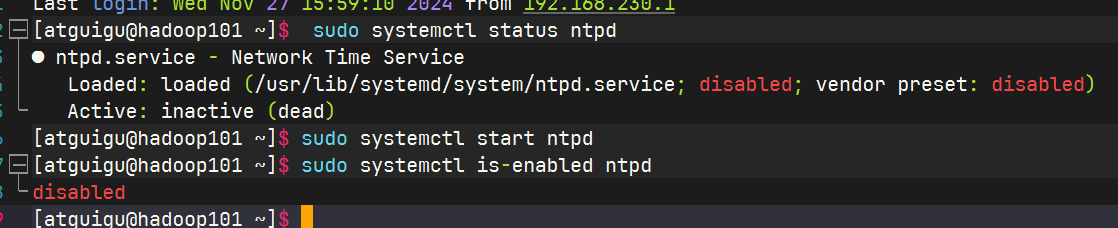
时间服务器配置(必须root用户)
查看所有节点ntpd服务状态和开机自启动状态
修改hadoop101的ntp.conf 配置文件
编辑文件
sudo vim /etc/ntp.conf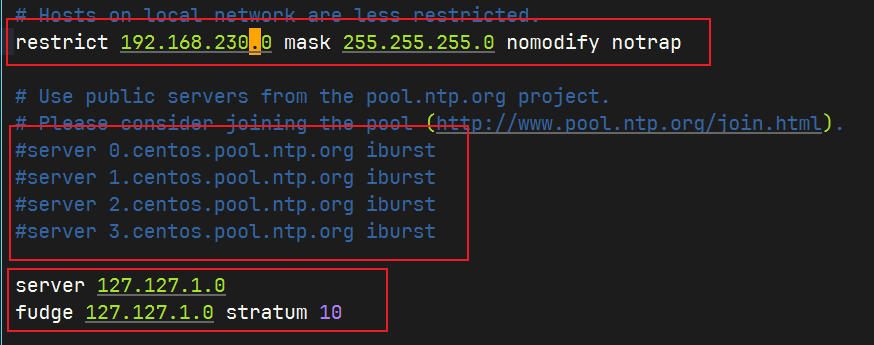
修改hadoop101的/etc/sysconfig/ntpd 文件
编辑文件
sudo vim /etc/sysconfig/ntpd增加内容如下(让硬件时间与系统时间一起同步)
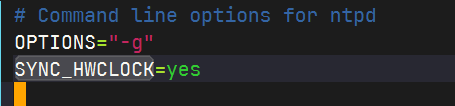
重新启动ntpd服务
使用指令
sudo systemctl start ntpd设置ntpd服务开机启动
使用指令
sudo systemctl enable ntpd
其他机器配置(必须root用户)
关闭所有节点上ntp服务和自启动
sudo systemctl stop ntpd sudo systemctl disable ntpd sudo systemctl stop ntpd sudo systemctl disable ntpd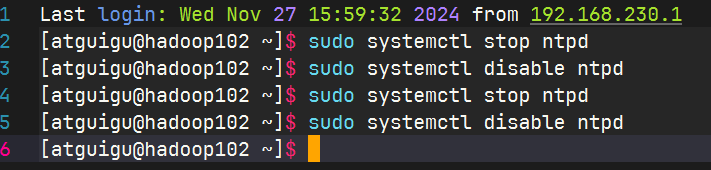
在其他机器配置1分钟与时间服务器同步一次
编写定时文件
sudo crontab -e
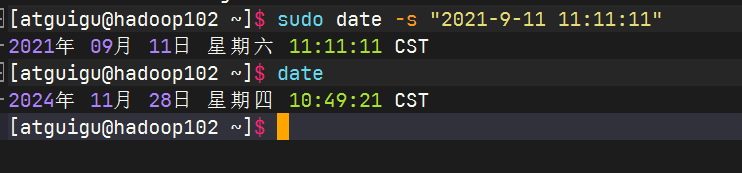
修改任意机器时间

1分钟后查看机器是否与时间服务器同步